 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Video Description With Cluster-Regularized Ensemble Ranking
Paper and Code
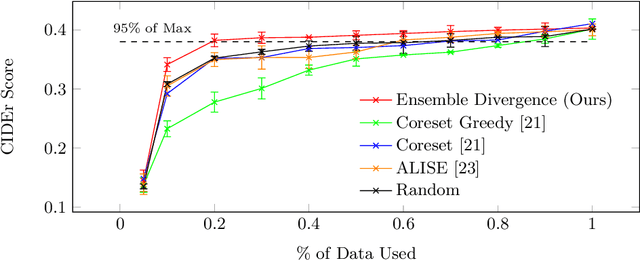
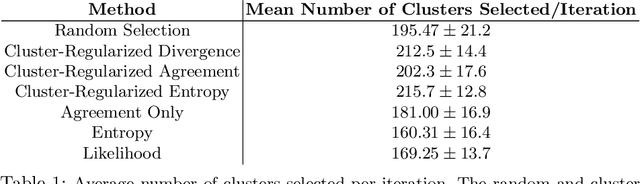
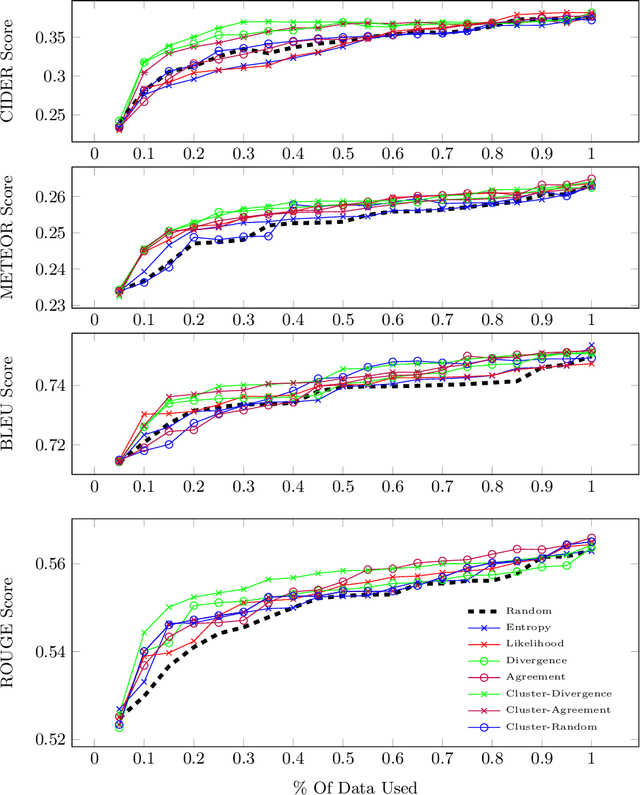
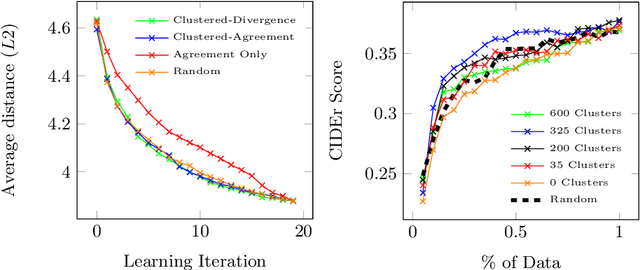
Automatic video captioning aims to train models to generate text descriptions for all segments in a video, however, the most effective approaches require large amounts of manual annotation which is slow and expensive. Active learning is a promising way to efficiently build a training set for video captioning tasks while reducing the need to manually label uninformative examples. In this work we both explore various active learning approaches for automatic video captioning and show that a cluster-regularized ensemble strategy provides the best active learning approach to efficiently gather training sets for video captioning. We evaluate our approaches on the MSR-VTT and LSMDC datasets using both transformer and LSTM based captioning models and show that our novel strategy can achieve high performance while using up to 60% fewer training data than the strong state of the art baselines.