 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Exploration via Experiment Design in Markov Chains
Paper and Code
Jun 29, 2022


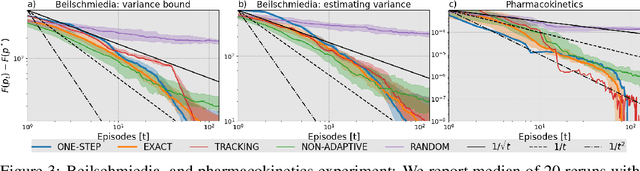
A key challenge in science and engineering is to design experiments to learn about some unknown quantity of interest. Classical experimental design optimally allocates the experimental budget to maximize a notion of utility (e.g., reduction in uncertainty about the unknown quantity). We consider a rich setting, where the experiments are associated with states in a {\em Markov chain}, and we can only choose them by selecting a {\em policy} controlling the state transitions. This problem captures important applications, from exploration in reinforcement learning to spatial monitoring tasks. We propose an algorithm -- \textsc{markov-design} -- that efficiently selects policies whose measurement allocation \emph{provably converges to the optimal one}. The algorithm is sequential in nature, adapting its choice of policies (experiments) informed by past measurements. In addition to our theoretical analysis, we showcase our framework on applications in ecological surveillance and pharmacology.