 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Conditioned Contrastive Policy Pretraining
Paper and Code
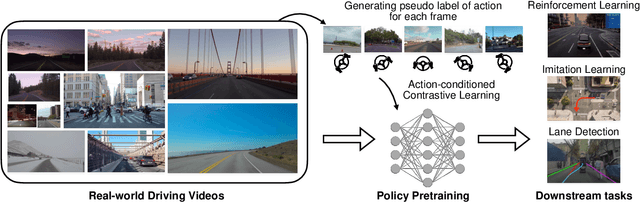



Deep visuomotor policy learning achieves promising results in control tasks such as robotic manipulation and autonomous driving, where the action is generated from the visual input by the neural policy. However, it requires a huge number of online interactions with the training environment, which limits its real-world application. Compared to the popular unsupervised feature learning for visual recognition, feature pretraining for visuomotor control tasks is much less explored. In this work, we aim to pretrain policy representations for driving tasks using hours-long uncurated YouTube videos. A new contrastive policy pretraining method is developed to learn action-conditioned features from video frames with action pseudo labels. Experiments show that the resulting action-conditioned features bring substantial improvements to the downstream reinforcement learning and imitation learning tasks, outperforming the weights pretrained from previous unsupervised learning methods. Code and models will be made publicly available.