 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcquiring Pronunciation Knowledge from Transcribed Speech Audio via Multi-task Learning
Paper and Code
Sep 15, 2024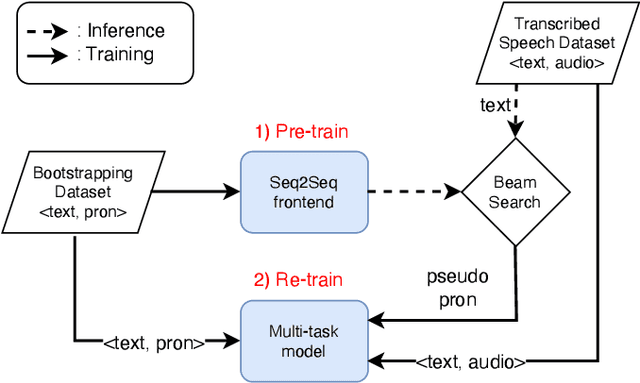
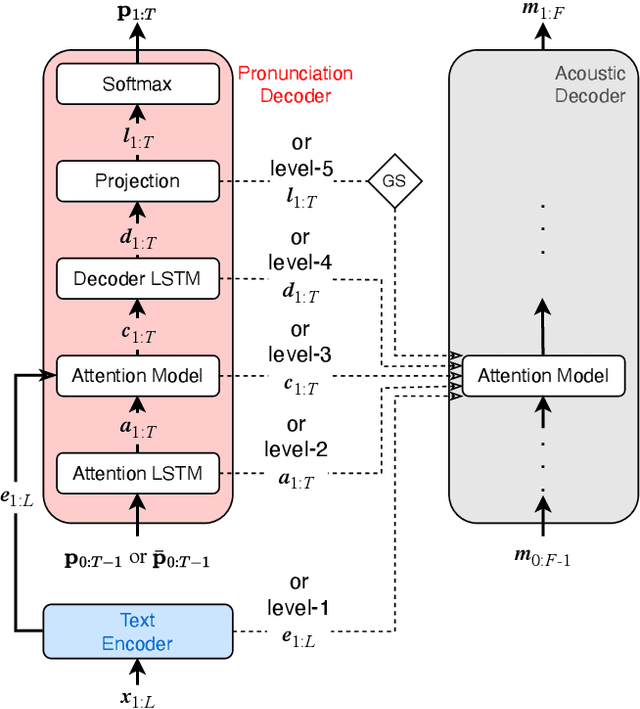
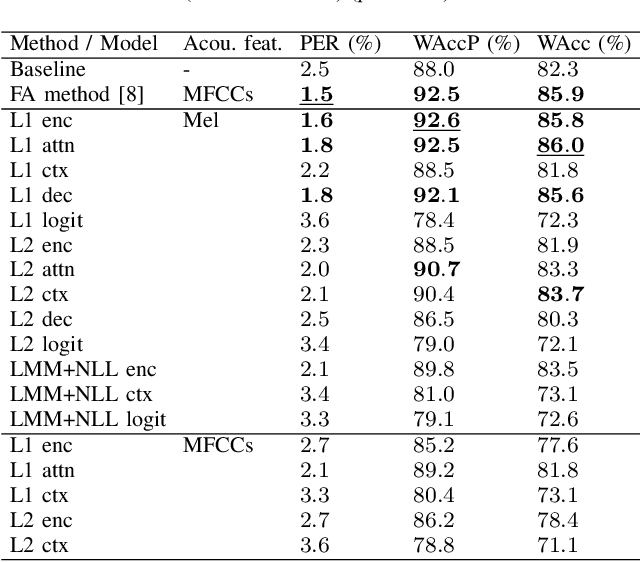
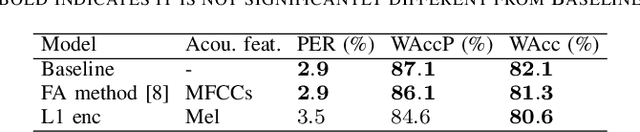
Recent work has shown the feasibility and benefit of bootstrapping an integrated sequence-to-sequence (Seq2Seq) linguistic frontend from a traditional pipeline-based frontend for text-to-speech (TTS). To overcome the fixed lexical coverage of bootstrapping training data, previous work has proposed to leverage easily accessible transcribed speech audio as an additional training source for acquiring novel pronunciation knowledge for uncovered words, which relies on an auxiliary ASR model as part of a cumbersome implementation flow. In this work, we propose an alternative method to leverage transcribed speech audio as an additional training source, based on multi-task learning (MTL). Experiments show that, compared to a baseline Seq2Seq frontend, the proposed MTL-based method reduces PER from 2.5% to 1.6% for those word types covered exclusively in transcribed speech audio, achieving a similar performance to the previous method but with a much simpler implementation flow.