 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate parameter estimation for Bayesian Network Classifiers using Hierarchical Dirichlet Processes
Paper and Code
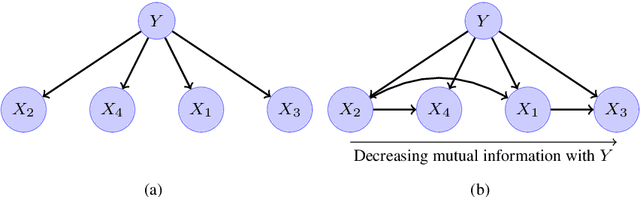

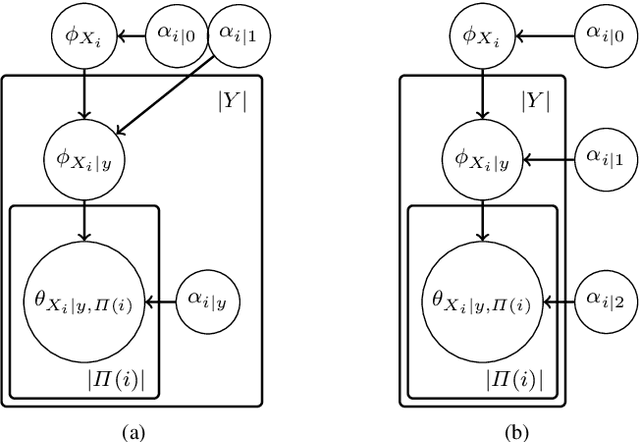

This paper introduces a novel parameter estimation method for the probability tables of Bayesian network classifiers (BNCs), using hierarchical Dirichlet processes (HDPs). The main result of this paper is to show that improved parameter estimation allows BNCs to outperform leading learning methods such as Random Forest for both 0-1 loss and RMSE, albeit just on categorical datasets. As data assets become larger, entering the hyped world of "big", efficient accurate classification requires three main elements: (1) classifiers with low-bias that can capture the fine-detail of large datasets (2) out-of-core learners that can learn from data without having to hold it all in main memory and (3) models that can classify new data very efficiently. The latest Bayesian network classifiers (BNCs) satisfy these requirements. Their bias can be controlled easily by increasing the number of parents of the nodes in the graph. Their structure can be learned out of core with a limited number of passes over the data. However, as the bias is made lower to accurately model classification tasks, so is the accuracy of their parameters' estimates, as each parameter is estimated from ever decreasing quantities of data. In this paper, we introduce the use of Hierarchical Dirichlet Processes for accurate BNC parameter estimation. We conduct an extensive set of experiments on 68 standard datasets and demonstrate that our resulting classifiers perform very competitively with Random Forest in terms of prediction, while keeping the out-of-core capability and superior classification time.