 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccessing Higher-level Representations in Sequential Transformers with Feedback Memory
Paper and Code
Mar 09, 2020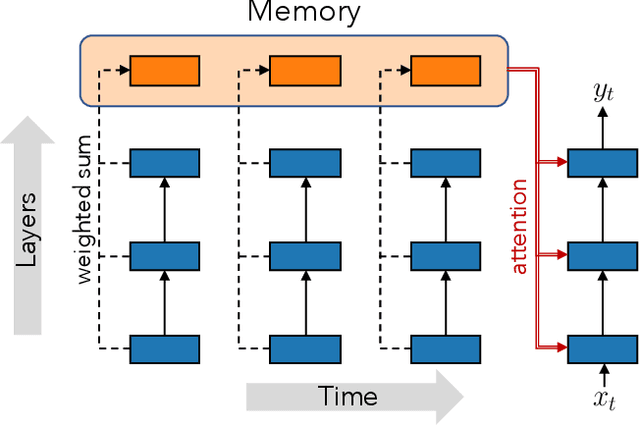
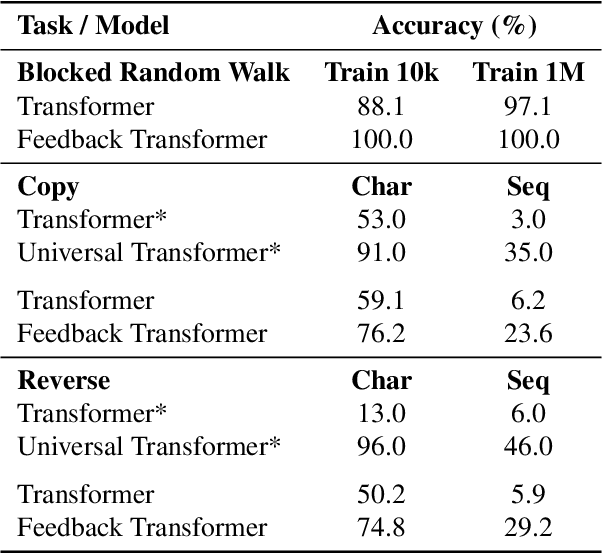


Transformers are feedforward networks that can process input tokens in parallel. While this parallelization makes them computationally efficient, it restricts the model from fully exploiting the sequential nature of the input - the representation at a given layer can only access representations from lower layers, rather than the higher level representations already built in previous time steps. In this work, we propose the Feedback Transformer architecture that exposes all previous representations to all future representations, meaning the lowest representation of the current timestep is formed from the highest-level abstract representation of the past. We demonstrate on a variety of benchmarks in language modeling, neural machine translation, summarization, and reinforcement learning that the increased representation capacity can improve over Transformer baselines.