 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcceleration for Compressed Gradient Descent in Distributed and Federated Optimization
Paper and Code
Feb 26, 2020
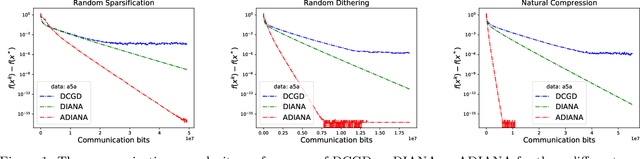


Due to the high communication cost in distributed and federated learning problems, methods relying on compression of communicated messages are becoming increasingly popular. While in other contexts the best performing gradient-type methods invariably rely on some form of acceleration/momentum to reduce the number of iterations, there are no methods which combine the benefits of both gradient compression and acceleration. In this paper, we remedy this situation and propose the first accelerated compressed gradient descent (ACGD) methods. In the single machine regime, we prove that ACGD enjoys the rate $O\left((1+\omega)\sqrt{\frac{L}{\mu}}\log \frac{1}{\epsilon}\right)$ for $\mu$-strongly convex problems and $O\left((1+\omega)\sqrt{\frac{L}{\epsilon}}\right)$ for convex problems, respectively, where $L$ is the smoothness constant and $\omega$ is the compression parameter. Our results improve upon the existing non-accelerated rates $O\left((1+\omega)\frac{L}{\mu}\log \frac{1}{\epsilon}\right)$ and $O\left((1+\omega)\frac{L}{\epsilon}\right)$, respectively, and recover the optimal rates of accelerated gradient descent as a special case when no compression ($\omega=0$) is applied. We further propose a distributed variant of ACGD (called ADIANA) and prove the convergence rate $\widetilde{O}\left(\omega+\sqrt{\frac{L}{\mu}} +\sqrt{\left(\frac{\omega}{n}+\sqrt{\frac{\omega}{n}}\right)\frac{\omega L}{\mu}}\right)$, where $n$ is the number of devices/workers and $\widetilde{O}$ hides the logarithmic factor $\log \frac{1}{\epsilon}$. This improves upon the previous best result $\widetilde{O}\left(\omega + \frac{L}{\mu}+\frac{\omega L}{n\mu} \right)$ achieved by the DIANA method of Mishchenko et al (2019). Finally, we conduct several experiments on real-world datasets which corroborate our theoretical results and confirm the practical superiority of our methods.