 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Exact and Approximate Inference for (Distributed) Discrete Optimization with GPUs
Paper and Code
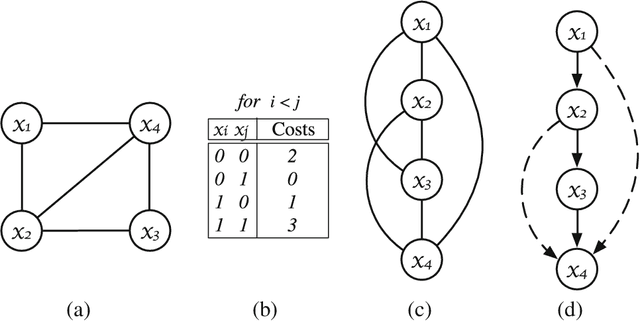
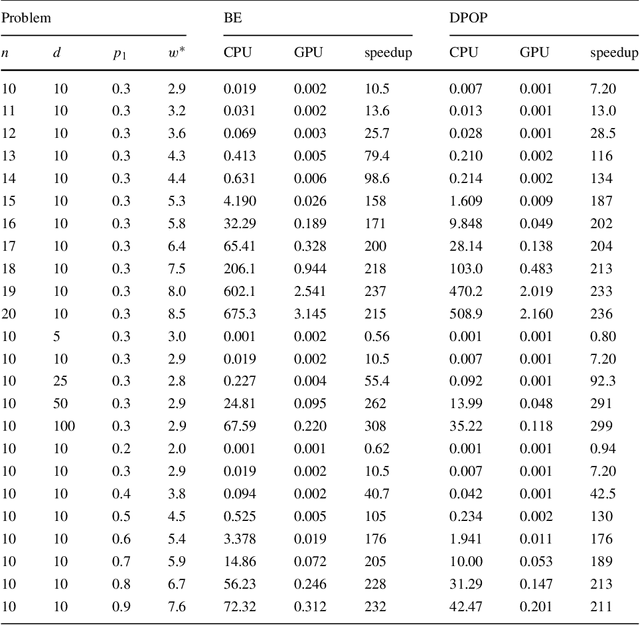
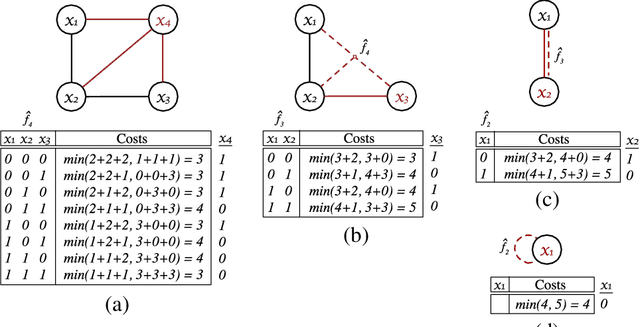
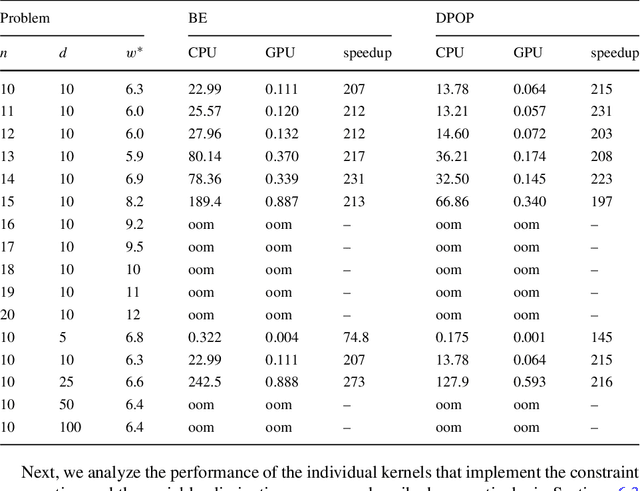
Discrete optimization is a central problem in artificial intelligence. The optimization of the aggregated cost of a network of cost functions arises in a variety of problems including (W)CSP, DCOP, as well as optimization in stochastic variants such as the tasks of finding the most probable explanation (MPE) in belief networks. Inference-based algorithms are powerful techniques for solving discrete optimization problems, which can be used independently or in combination with other techniques. However, their applicability is often limited by their compute intensive nature and their space requirements. This paper proposes the design and implementation of a novel inference-based technique, which exploits modern massively parallel architectures, such as those found in Graphical Processing Units (GPUs), to speed up the resolution of exact and approximated inference-based algorithms for discrete optimization. The paper studies the proposed algorithm in both centralized and distributed optimization contexts. The paper demonstrates that the use of GPUs provides significant advantages in terms of runtime and scalability, achieving up to two orders of magnitude in speedups and showing a considerable reduction in execution time (up to 345 times faster) with respect to a sequential version.