 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Proximal Alternating Gradient-Descent-Ascent for Nonconvex Minimax Machine Learning
Paper and Code
Dec 30, 2021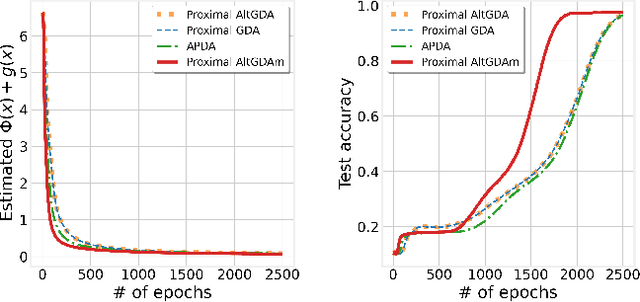
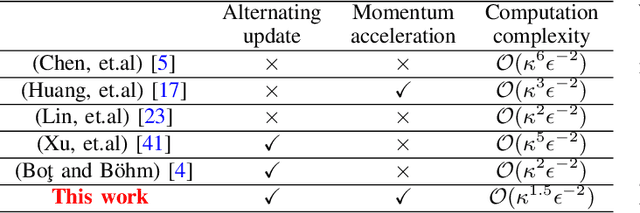
Alternating gradient-descent-ascent (AltGDA) is an optimization algorithm that has been widely used for model training in various machine learning applications, which aim to solve a nonconvex minimax optimization problem. However, the existing studies show that it suffers from a high computation complexity in nonconvex minimax optimization. In this paper, we develop a single-loop and fast AltGDA-type algorithm that leverages proximal gradient updates and momentum acceleration to solve regularized nonconvex minimax optimization problems. By identifying the intrinsic Lyapunov function of this algorithm, we prove that it converges to a critical point of the nonconvex minimax optimization problem and achieves a computation complexity $\mathcal{O}(\kappa^{1.5}\epsilon^{-2})$, where $\epsilon$ is the desired level of accuracy and $\kappa$ is the problem's condition number. Such a computation complexity improves the state-of-the-art complexities of single-loop GDA and AltGDA algorithms (see the summary of comparison in Table 1). We demonstrate the effectiveness of our algorithm via an experiment on adversarial deep learning.