 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Version of Geiringer-like Theorem for Decision Making in the Environments with Randomness and Incomplete Information
Paper and Code
Oct 20, 2011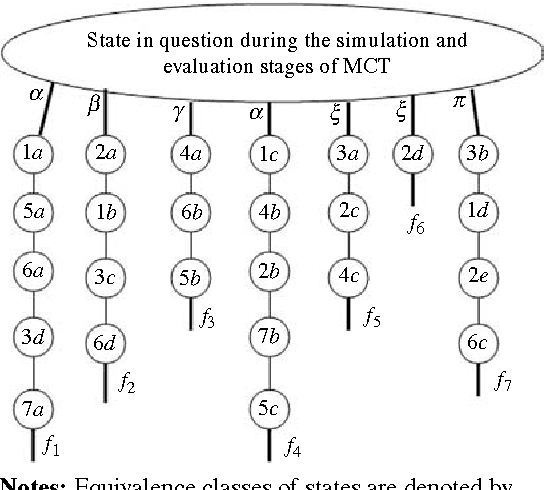
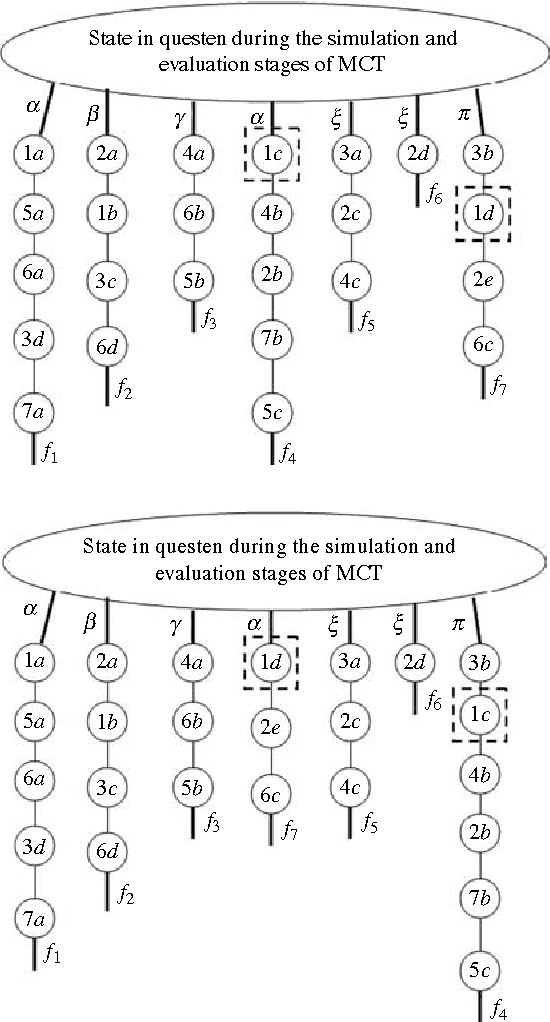
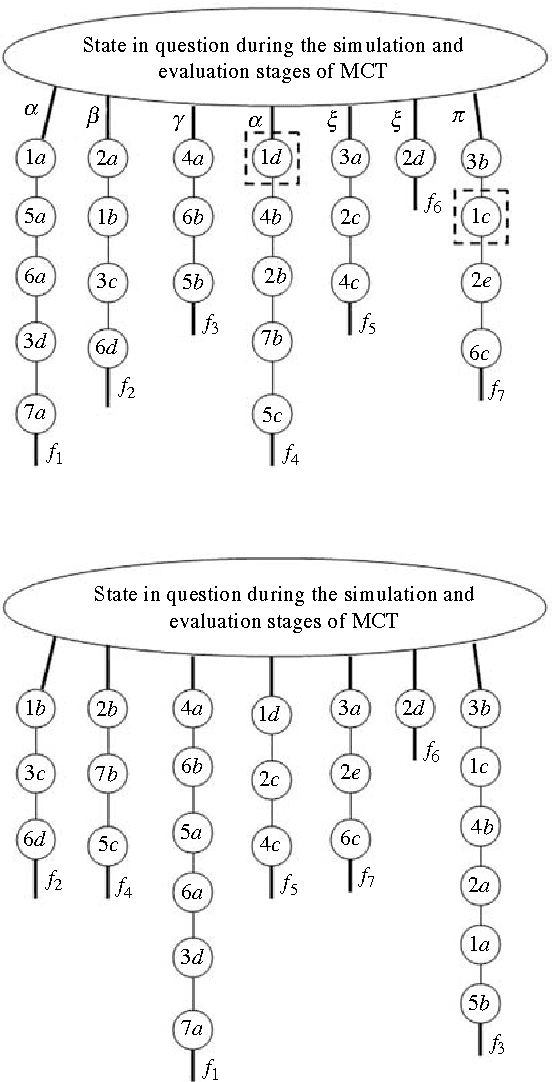
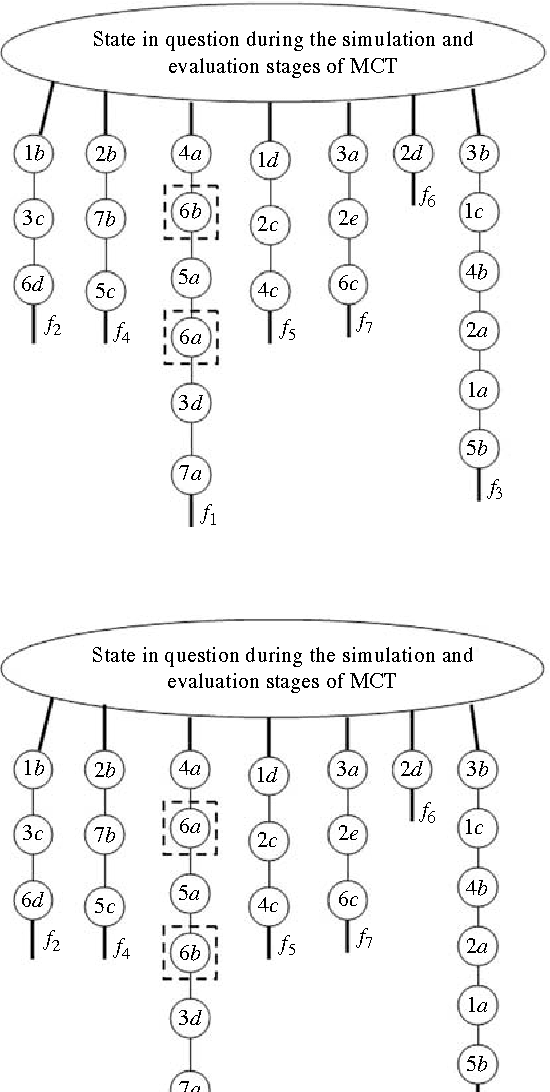
Purpose: In recent years Monte-Carlo sampling methods, such as Monte Carlo tree search, have achieved tremendous success in model free reinforcement learning. A combination of the so called upper confidence bounds policy to preserve the "exploration vs. exploitation" balance to select actions for sample evaluations together with massive computing power to store and to update dynamically a rather large pre-evaluated game tree lead to the development of software that has beaten the top human player in the game of Go on a 9 by 9 board. Much effort in the current research is devoted to widening the range of applicability of the Monte-Carlo sampling methodology to partially observable Markov decision processes with non-immediate payoffs. The main challenge introduced by randomness and incomplete information is to deal with the action evaluation at the chance nodes due to drastic differences in the possible payoffs the same action could lead to. The aim of this article is to establish a version of a theorem that originated from population genetics and has been later adopted in evolutionary computation theory that will lead to novel Monte-Carlo sampling algorithms that provably increase the AI potential. Due to space limitations the actual algorithms themselves will be presented in the sequel papers, however, the current paper provides a solid mathematical foundation for the development of such algorithms and explains why they are so promising.