 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Variational View on Bootstrap Ensembles as Bayesian Inference
Paper and Code



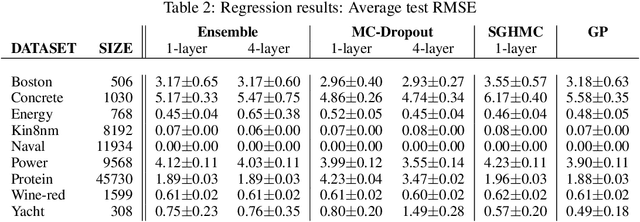
In this paper, we employ variational arguments to establish a connection between ensemble methods for Neural Networks and Bayesian inference. We consider an ensemble-based scheme where each model/particle corresponds to a perturbation of the data by means of parametric bootstrap and a perturbation of the prior. We derive conditions under which any optimization steps of the particles makes the associated distribution reduce its divergence to the posterior over model parameters. Such conditions do not require any particular form for the approximation and they are purely geometrical, giving insights on the behavior of the ensemble on a number of interesting models such as Neural Networks with ReLU activations. Experiments confirm that ensemble methods can be a valid alternative to approximate Bayesian inference; the theoretical developments in the paper seek to explain this behavior.