 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Uniformly Stable Algorithm For Unsupervised Feature Selection
Paper and Code


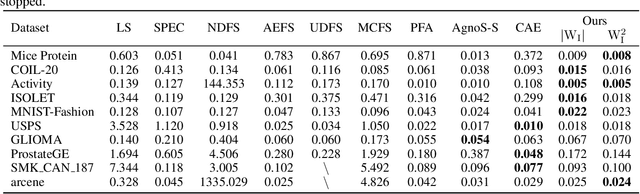

High-dimensional data presents challenges for data management. Feature selection, as an important dimensionality reduction technique, reduces the dimensionality of data by identifying an essential subset of input features, and it can provide interpretable, effective, and efficient insights for analysis and decision-making processes. Algorithmic stability is a key characteristic of an algorithm in its sensitivity to perturbations of input samples. In this paper, first we propose an innovative unsupervised feature selection algorithm. The architecture of our algorithm consists of a feature scorer and a feature selector. The scorer trains a neural network (NN) to score all the features globally, and the selector is in a dependence sub-NN which locally evaluates the representation abilities to select features. Further, we present algorithmic stability analysis and show our algorithm has a performance guarantee by providing a generalization error bound. Empirically, extensive experimental results on ten real-world datasets corroborate the superior generalization performance of our algorithm over contemporary algorithms. Notably, the features selected by our algorithm have comparable performance to the original features; therefore, our algorithm significantly facilitates data management.