 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Uniform Confidence Phenomenon in Deep Learning and its Implications for Calibration
Paper and Code
Jun 01, 2023
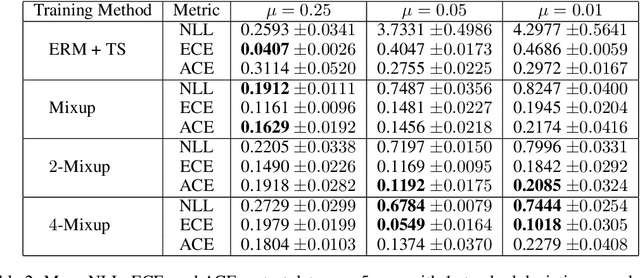
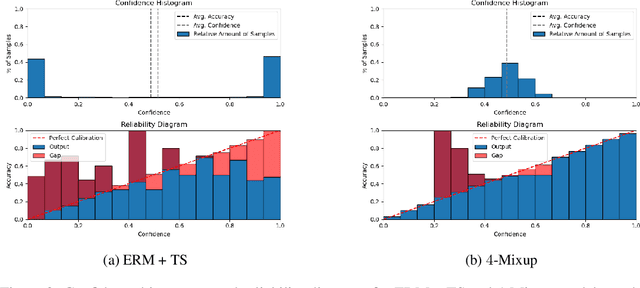
Despite the impressive generalization capabilities of deep neural networks, they have been repeatedly shown to poorly estimate their predictive uncertainty - in other words, they are frequently overconfident when they are wrong. Fixing this issue is known as model calibration, and has consequently received much attention in the form of modified training schemes and post-training calibration procedures. In this work, we present a significant hurdle to the calibration of modern models: deep neural networks have large neighborhoods of almost certain confidence around their training points. We demonstrate in our experiments that this phenomenon consistently arises (in the context of image classification) across many model and dataset pairs. Furthermore, we prove that when this phenomenon holds, for a large class of data distributions with overlaps between classes, it is not possible to obtain a model that is asymptotically better than random (with respect to calibration) even after applying the standard post-training calibration technique of temperature scaling. On the other hand, we also prove that it is possible to circumvent this defect by changing the training process to use a modified loss based on the Mixup data augmentation technique.