 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Study of Machine Learning Explanation Evaluation Metrics
Paper and Code
Mar 27, 2022


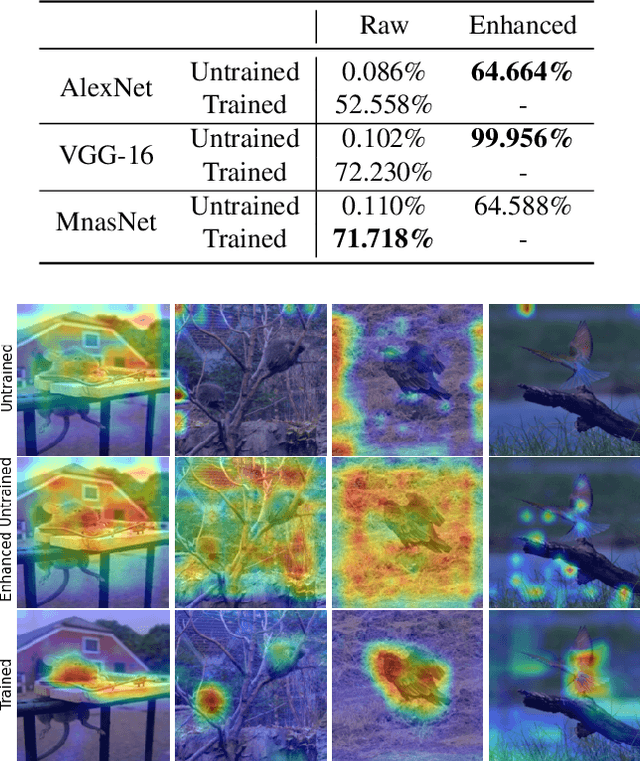
The growing need for trustworthy machine learning has led to the blossom of interpretability research. Numerous explanation methods have been developed to serve this purpose. However, these methods are deficiently and inappropriately evaluated. Many existing metrics for explanations are introduced by researchers as by-products of their proposed explanation techniques to demonstrate the advantages of their methods. Although widely used, they are more or less accused of problems. We claim that the lack of acknowledged and justified metrics results in chaos in benchmarking these explanation methods -- Do we really have good/bad explanation when a metric gives a high/low score? We split existing metrics into two categories and demonstrate that they are insufficient to properly evaluate explanations for multiple reasons. We propose guidelines in dealing with the problems in evaluating machine learning explanation and encourage researchers to carefully deal with these problems when developing explanation techniques and metrics.