 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA tutorial on conformal prediction
Paper and Code



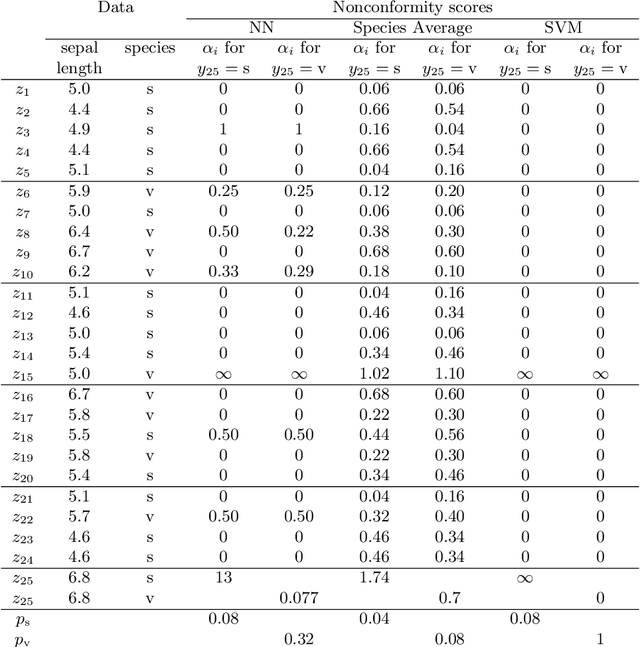
Conformal prediction uses past experience to determine precise levels of confidence in new predictions. Given an error probability $\epsilon$, together with a method that makes a prediction $\hat{y}$ of a label $y$, it produces a set of labels, typically containing $\hat{y}$, that also contains $y$ with probability $1-\epsilon$. Conformal prediction can be applied to any method for producing $\hat{y}$: a nearest-neighbor method, a support-vector machine, ridge regression, etc. Conformal prediction is designed for an on-line setting in which labels are predicted successively, each one being revealed before the next is predicted. The most novel and valuable feature of conformal prediction is that if the successive examples are sampled independently from the same distribution, then the successive predictions will be right $1-\epsilon$ of the time, even though they are based on an accumulating dataset rather than on independent datasets. In addition to the model under which successive examples are sampled independently, other on-line compression models can also use conformal prediction. The widely used Gaussian linear model is one of these. This tutorial presents a self-contained account of the theory of conformal prediction and works through several numerical examples. A more comprehensive treatment of the topic is provided in "Algorithmic Learning in a Random World", by Vladimir Vovk, Alex Gammerman, and Glenn Shafer (Springer, 2005).