 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Transistor Operations Model for Deep Learning Energy Consumption Scaling
Paper and Code
May 30, 2022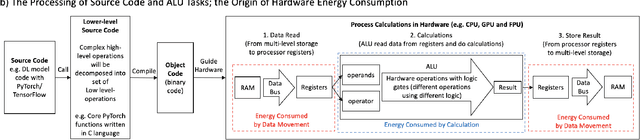
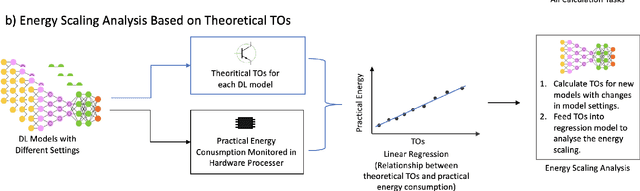
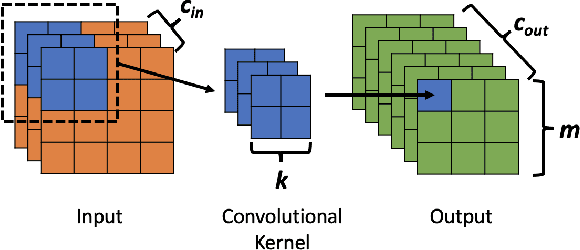
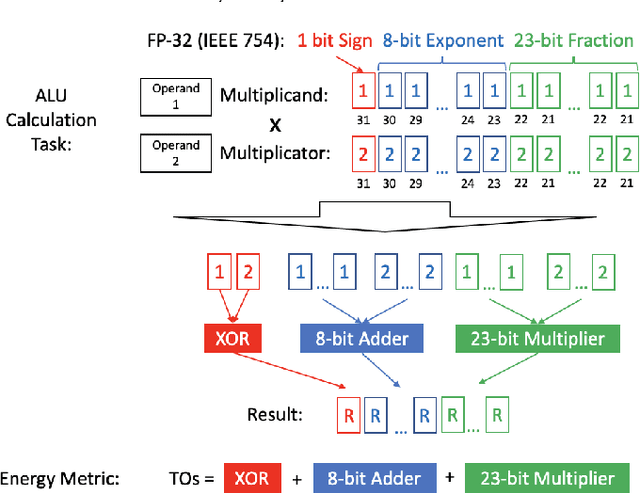
Deep Learning (DL) has transformed the automation of a wide range of industries and finds increasing ubiquity in society. The increasing complexity of DL models and its widespread adoption has led to the energy consumption doubling every 3-4 months. Currently, the relationship between DL model configuration and energy consumption is not well established. Current FLOPs and MACs based methods only consider the linear operations. In this paper, we develop a bottom-level Transistor Operations (TOs) method to expose the role of activation functions and neural network structure in energy consumption scaling with DL model configuration. TOs allows us uncovers the role played by non-linear operations (e.g. division/root operations performed by activation functions and batch normalisation). As such, our proposed TOs model provides developers with a hardware-agnostic index for how energy consumption scales with model settings. To validate our work, we analyse the TOs energy scaling of a feed-forward DNN model set and achieve a 98.2% - 99.97% precision in estimating its energy consumption. We believe this work can be extended to any DL model.