 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA study on the plasticity of neural networks
Paper and Code
May 31, 2021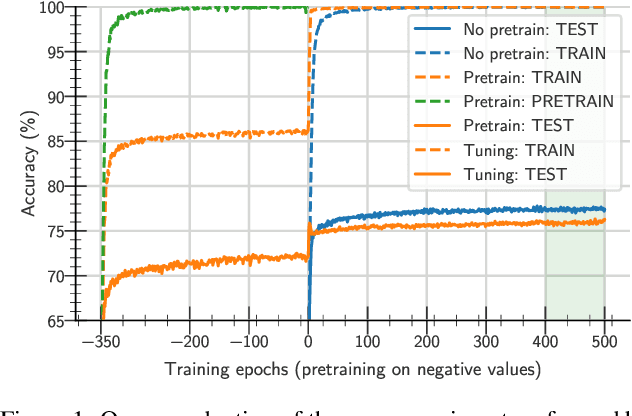
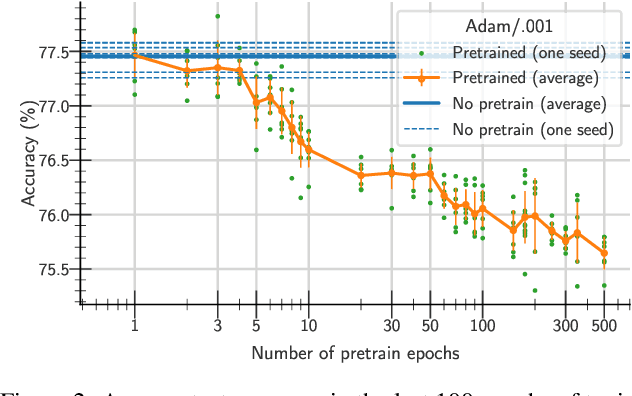
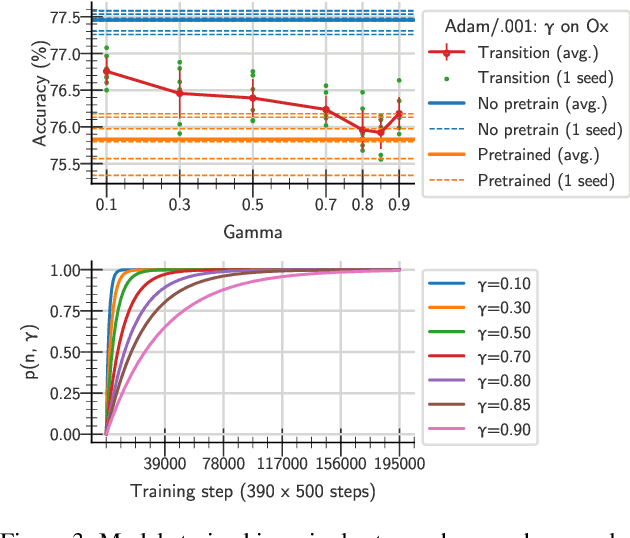
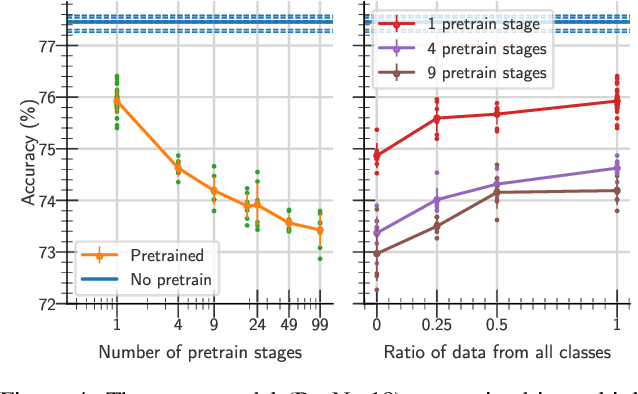
One aim shared by multiple settings, such as continual learning or transfer learning, is to leverage previously acquired knowledge to converge faster on the current task. Usually this is done through fine-tuning, where an implicit assumption is that the network maintains its plasticity, meaning that the performance it can reach on any given task is not affected negatively by previously seen tasks. It has been observed recently that a pretrained model on data from the same distribution as the one it is fine-tuned on might not reach the same generalisation as a freshly initialised one. We build and extend this observation, providing a hypothesis for the mechanics behind it. We discuss the implication of losing plasticity for continual learning which heavily relies on optimising pretrained models.