 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Modeling Rising Intonation in Cantonese Neural Speech Synthesis
Paper and Code
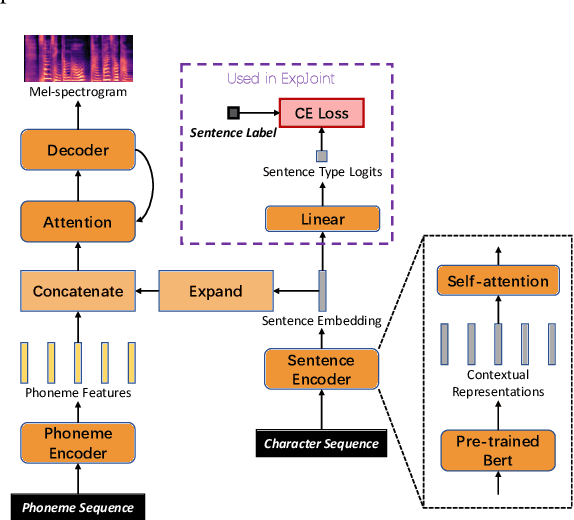
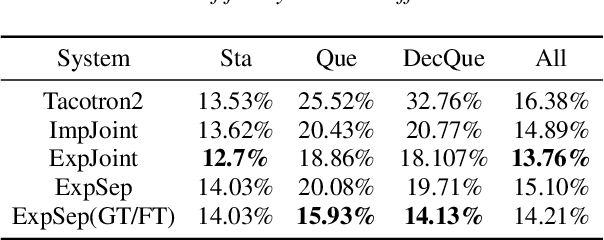
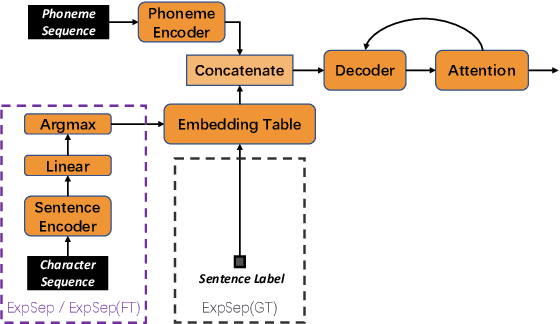
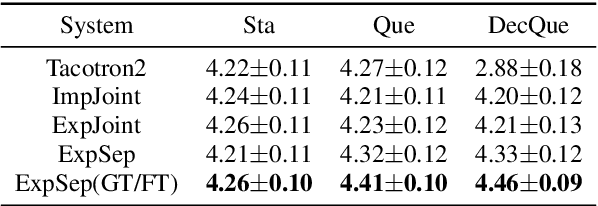
In human speech, the attitude of a speaker cannot be fully expressed only by the textual content. It has to come along with the intonation. Declarative questions are commonly used in daily Cantonese conversations, and they are usually uttered with rising intonation. Vanilla neural text-to-speech (TTS) systems are not capable of synthesizing rising intonation for these sentences due to the loss of semantic information. Though it has become more common to complement the systems with extra language models, their performance in modeling rising intonation is not well studied. In this paper, we propose to complement the Cantonese TTS model with a BERT-based statement/question classifier. We design different training strategies and compare their performance. We conduct our experiments on a Cantonese corpus named CanTTS. Empirical results show that the separate training approach obtains the best generalization performance and feasibility.