 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Statistical Approach to Set Classification by Feature Selection with Applications to Classification of Histopathology Images
Paper and Code
Feb 19, 2014
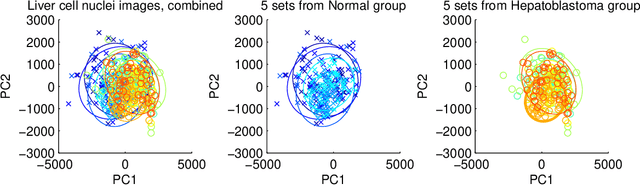


Set classification problems arise when classification tasks are based on sets of observations as opposed to individual observations. In set classification, a classification rule is trained with $N$ sets of observations, where each set is labeled with class information, and the prediction of a class label is performed also with a set of observations. Data sets for set classification appear, for example, in diagnostics of disease based on multiple cell nucleus images from a single tissue. Relevant statistical models for set classification are introduced, which motivate a set classification framework based on context-free feature extraction. By understanding a set of observations as an empirical distribution, we employ a data-driven method to choose those features which contain information on location and major variation. In particular, the method of principal component analysis is used to extract the features of major variation. Multidimensional scaling is used to represent features as vector-valued points on which conventional classifiers can be applied. The proposed set classification approaches achieve better classification results than competing methods in a number of simulated data examples. The benefits of our method are demonstrated in an analysis of histopathology images of cell nuclei related to liver cancer.