 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA State Augmentation based approach to Reinforcement Learning from Human Preferences
Paper and Code
Feb 17, 2023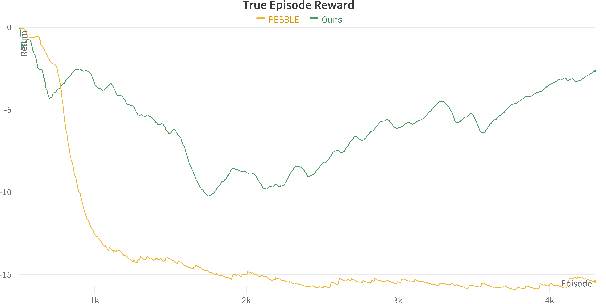
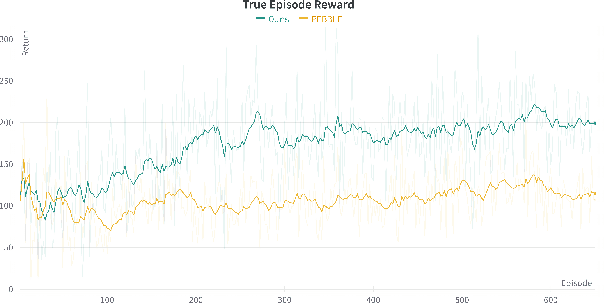
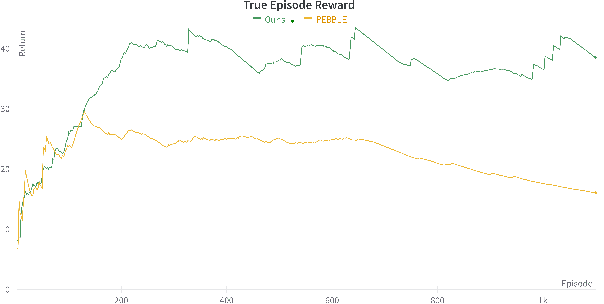
Reinforcement Learning has suffered from poor reward specification, and issues for reward hacking even in simple enough domains. Preference Based Reinforcement Learning attempts to solve the issue by utilizing binary feedbacks on queried trajectory pairs by a human in the loop indicating their preferences about the agent's behavior to learn a reward model. In this work, we present a state augmentation technique that allows the agent's reward model to be robust and follow an invariance consistency that significantly improved performance, i.e. the reward recovery and subsequent return computed using the learned policy over our baseline PEBBLE. We validate our method on three domains, Mountain Car, a locomotion task of Quadruped-Walk, and a robotic manipulation task of Sweep-Into, and find that using the proposed augmentation the agent not only benefits in the overall performance but does so, quite early in the agent's training phase.