 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Snapshot of the Frontiers of Client Selection in Federated Learning
Paper and Code

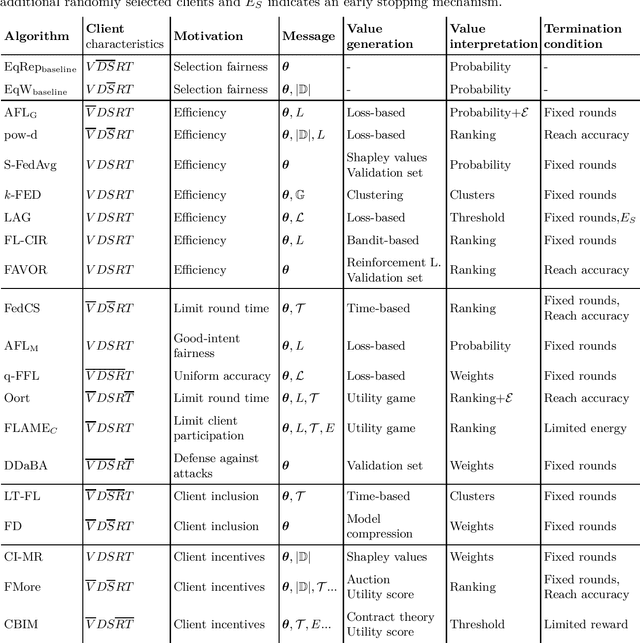
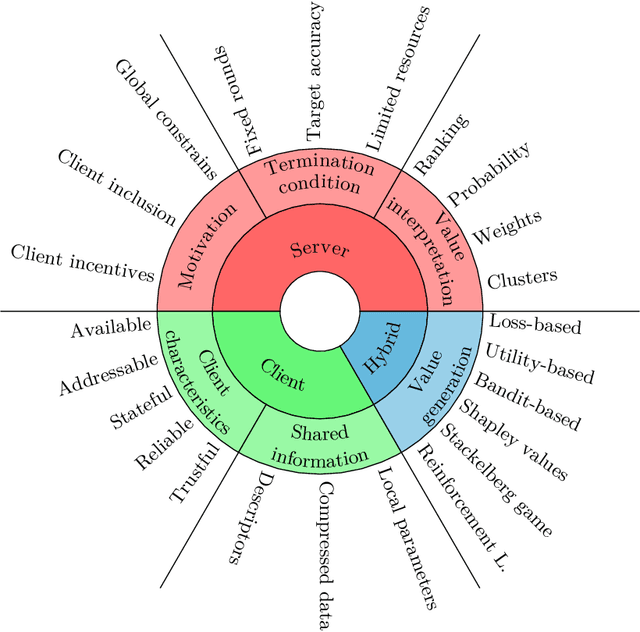
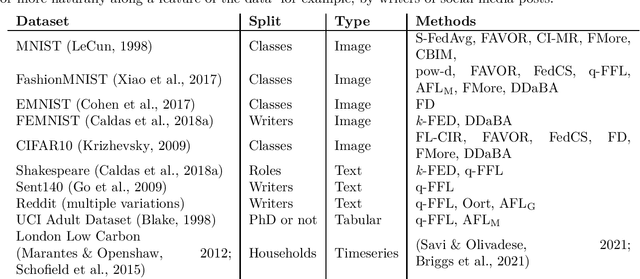
Federated learning (FL) has been proposed as a privacy-preserving approach in distributed machine learning. A federated learning architecture consists of a central server and a number of clients that have access to private, potentially sensitive data. Clients are able to keep their data in their local machines and only share their locally trained model's parameters with a central server that manages the collaborative learning process. FL has delivered promising results in real-life scenarios, such as healthcare, energy, and finance. However, when the number of participating clients is large, the overhead of managing the clients slows down the learning. Thus, client selection has been introduced as a strategy to limit the number of communicating parties at every step of the process. Since the early na\"{i}ve random selection of clients, several client selection methods have been proposed in the literature. Unfortunately, given that this is an emergent field, there is a lack of a taxonomy of client selection methods, making it hard to compare approaches. In this paper, we propose a taxonomy of client selection in Federated Learning that enables us to shed light on current progress in the field and identify potential areas of future research in this promising area of machine learning.