Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Approach to Sparse Clustering
Paper and Code
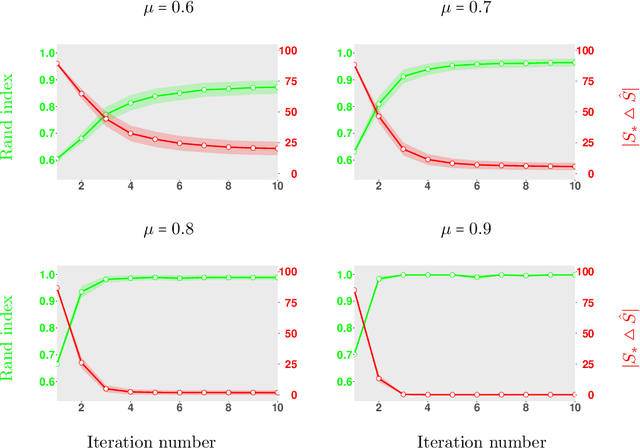
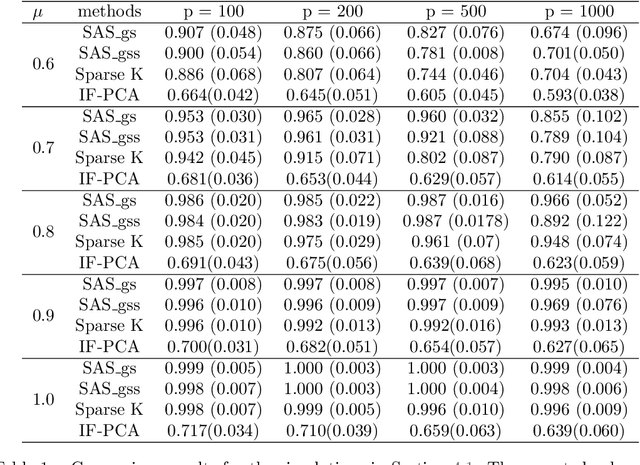
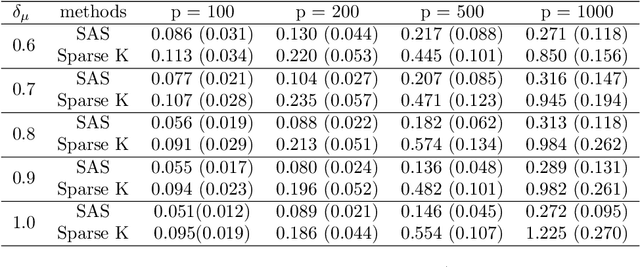
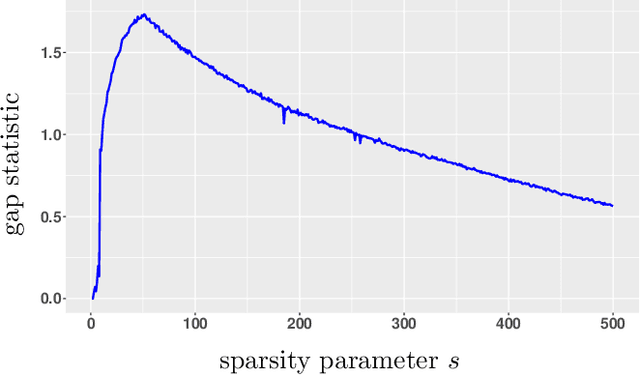
Consider the problem of sparse clustering, where it is assumed that only a subset of the features are useful for clustering purposes. In the framework of the COSA method of Friedman and Meulman, subsequently improved in the form of the Sparse K-means method of Witten and Tibshirani, a natural and simpler hill-climbing approach is introduced. The new method is shown to be competitive with these two methods and others.
* Computational Statistics & Data Analysis. 2017 Jan 31
View paper on