 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sentence-level Hierarchical BERT Model for Document Classification with Limited Labelled Data
Paper and Code
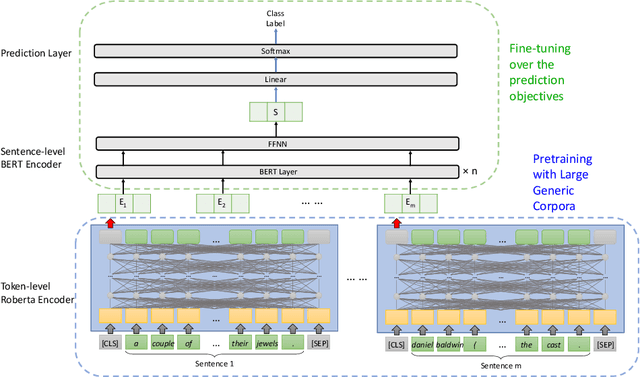
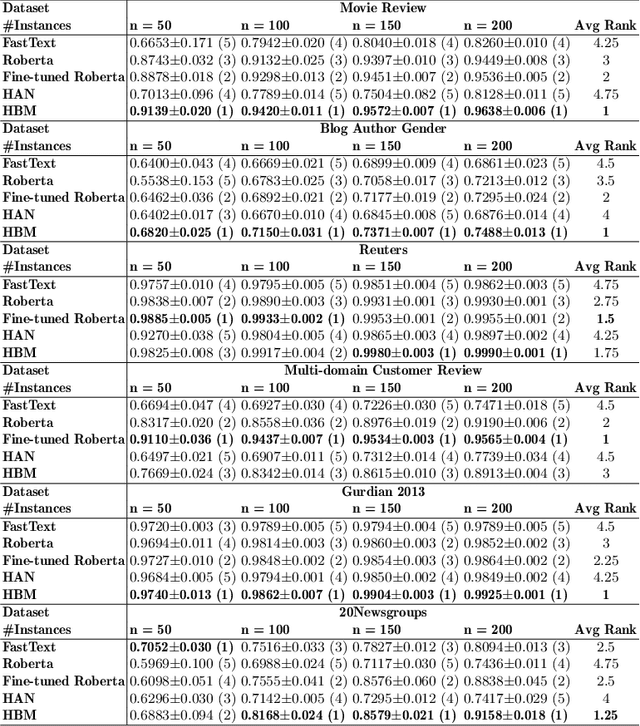
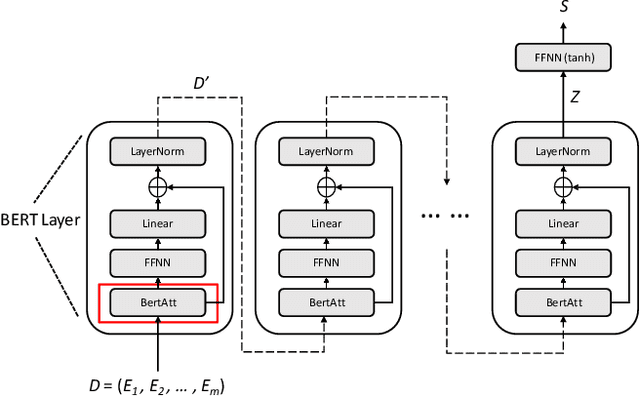

Training deep learning models with limited labelled data is an attractive scenario for many NLP tasks, including document classification. While with the recent emergence of BERT, deep learning language models can achieve reasonably good performance in document classification with few labelled instances, there is a lack of evidence in the utility of applying BERT-like models on long document classification. This work introduces a long-text-specific model -- the Hierarchical BERT Model (HBM) -- that learns sentence-level features of the text and works well in scenarios with limited labelled data. Various evaluation experiments have demonstrated that HBM can achieve higher performance in document classification than the previous state-of-the-art methods with only 50 to 200 labelled instances, especially when documents are long. Also, as an extra benefit of HBM, the salient sentences identified by learned HBM are useful as explanations for labelling documents based on a user study.