 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA self consistent theory of Gaussian Processes captures feature learning effects in finite CNNs
Paper and Code
Jun 08, 2021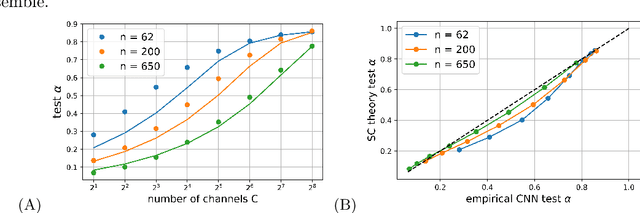
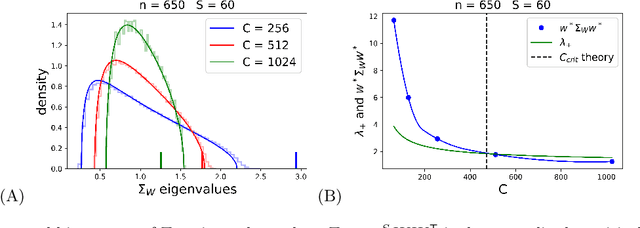
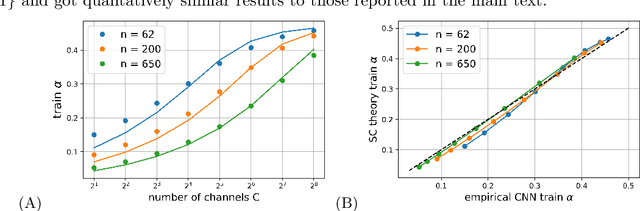
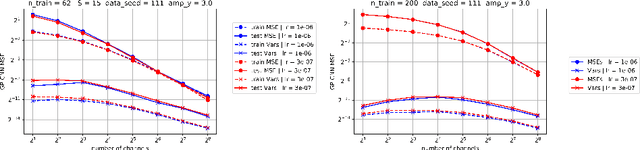
Deep neural networks (DNNs) in the infinite width/channel limit have received much attention recently, as they provide a clear analytical window to deep learning via mappings to Gaussian Processes (GPs). Despite its theoretical appeal, this viewpoint lacks a crucial ingredient of deep learning in finite DNNs, laying at the heart of their success -- feature learning. Here we consider DNNs trained with noisy gradient descent on a large training set and derive a self consistent Gaussian Process theory accounting for strong finite-DNN and feature learning effects. Applying this to a toy model of a two-layer linear convolutional neural network (CNN) shows good agreement with experiments. We further identify, both analytical and numerically, a sharp transition between a feature learning regime and a lazy learning regime in this model. Strong finite-DNN effects are also derived for a non-linear two-layer fully connected network. Our self consistent theory provides a rich and versatile analytical framework for studying feature learning and other non-lazy effects in finite DNNs.