 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA review of single-source unsupervised domain adaptation
Paper and Code
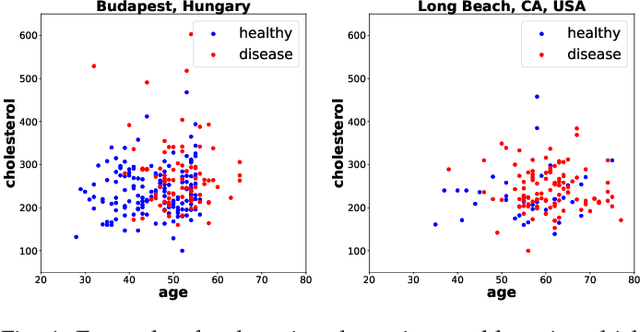

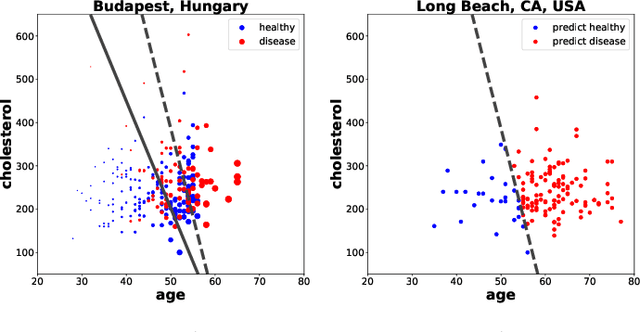

Domain adaptation has become a prominent problem setting in machine learning and related fields. This review asks the questions: when and how a classifier can learn from a source domain and generalize to a target domain. As for when, we review conditions that allow for cross-domain generalization error bounds. As for how, we present a categorization of approaches, divided into, what we refer to as, sample-based, feature-based and inference-based methods. Sample-based methods focus on weighting individual observations during training based on their importance to the target domain. Feature-based methods focus on mapping, projecting and representing features such that a source classifier performs well on the target domain and inference-based methods focus on alternative estimators, such as robust, minimax or Bayesian. Our categorization highlights recurring ideas and raises a number of questions important to further research.