 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reverse Mamba Attention Network for Pathological Liver Segmentation
Paper and Code
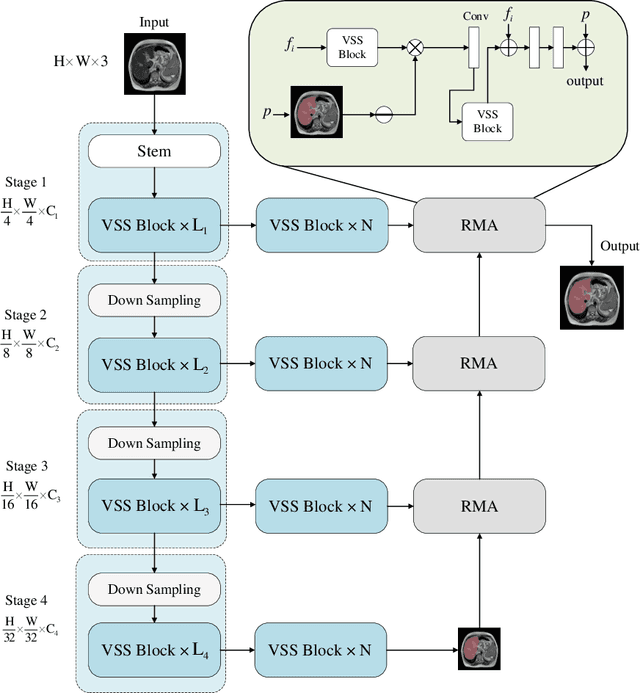



We present RMA-Mamba, a novel architecture that advances the capabilities of vision state space models through a specialized reverse mamba attention module (RMA). The key innovation lies in RMA-Mamba's ability to capture long-range dependencies while maintaining precise local feature representation through its hierarchical processing pipeline. By integrating Vision Mamba (VMamba)'s efficient sequence modeling with RMA's targeted feature refinement, our architecture achieves superior feature learning across multiple scales. This dual-mechanism approach enables robust handling of complex morphological patterns while maintaining computational efficiency. We demonstrate RMA-Mamba's effectiveness in the challenging domain of pathological liver segmentation (from both CT and MRI), where traditional segmentation approaches often fail due to tissue variations. When evaluated on a newly introduced cirrhotic liver dataset (CirrMRI600+) of T2-weighted MRI scans, RMA-Mamba achieves the state-of-the-art performance with a Dice coefficient of 92.08%, mean IoU of 87.36%, and recall of 92.96%. The architecture's generalizability is further validated on the cancerous liver segmentation from CT scans (LiTS: Liver Tumor Segmentation dataset), yielding a Dice score of 92.9% and mIoU of 88.99%. The source code of the proposed RMA-Mamba is available at https://github.com/JunZengz/RMAMamba.