Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reinforcement Learning Perspective on the Optimal Control of Mutation Probabilities for the (1+1) Evolutionary Algorithm: First Results on the OneMax Problem
Paper and Code
May 09, 2019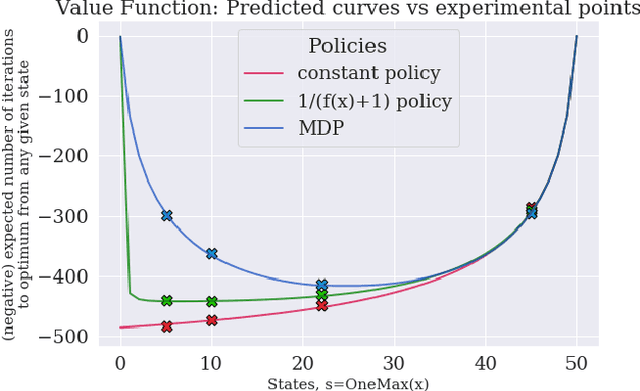
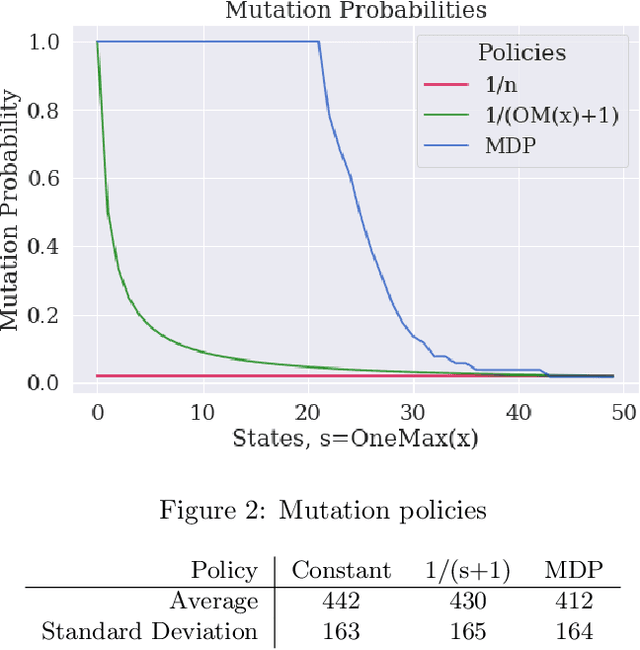
We study how Reinforcement Learning can be employed to optimally control parameters in evolutionary algorithms. We control the mutation probability of a (1+1) evolutionary algorithm on the OneMax function. This problem is modeled as a Markov Decision Process and solved with Value Iteration via the known transition probabilities. It is then solved via Q-Learning, a Reinforcement Learning algorithm, where the exact transition probabilities are not needed. This approach also allows previous expert or empirical knowledge to be included into learning. It opens new perspectives, both formally and computationally, for the problem of parameter control in optimization.
View paper on