 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Regression Tsetlin Machine with Integer Weighted Clauses for Compact Pattern Representation
Paper and Code
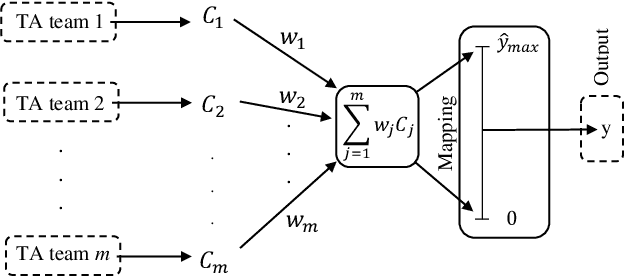

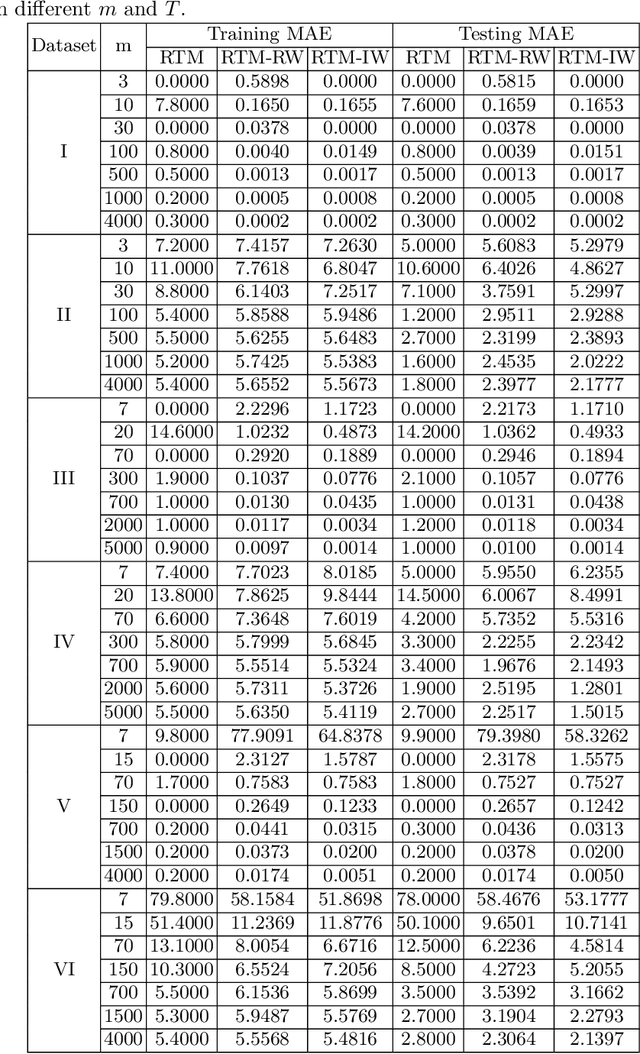
The Regression Tsetlin Machine (RTM) addresses the lack of interpretability impeding state-of-the-art nonlinear regression models. It does this by using conjunctive clauses in propositional logic to capture the underlying non-linear frequent patterns in the data. These, in turn, are combined into a continuous output through summation, akin to a linear regression function, however, with non-linear components and unity weights. Although the RTM has solved non-linear regression problems with competitive accuracy, the resolution of the output is proportional to the number of clauses employed. This means that computation cost increases with resolution. To reduce this problem, we here introduce integer weighted RTM clauses. Our integer weighted clause is a compact representation of multiple clauses that capture the same sub-pattern-N repeating clauses are turned into one, with an integer weight N. This reduces computation cost N times, and increases interpretability through a sparser representation. We further introduce a novel learning scheme that allows us to simultaneously learn both the clauses and their weights, taking advantage of so-called stochastic searching on the line. We evaluate the potential of the integer weighted RTM empirically using six artificial datasets. The results show that the integer weighted RTM is able to acquire on par or better accuracy using significantly less computational resources compared to regular RTMs. We further show that integer weights yield improved accuracy over real-valued ones.