 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reconstruction Error Formulation for Semi-Supervised Multi-task and Multi-view Learning
Paper and Code
Feb 04, 2012
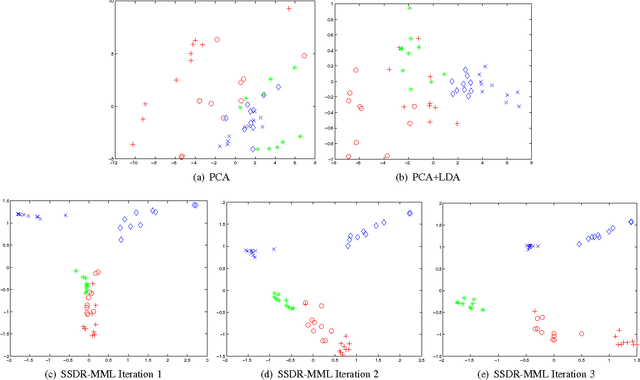
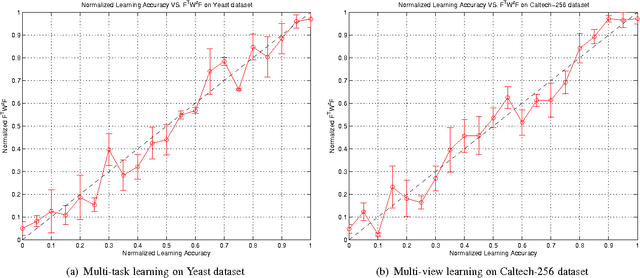
A significant challenge to make learning techniques more suitable for general purpose use is to move beyond i) complete supervision, ii) low dimensional data, iii) a single task and single view per instance. Solving these challenges allows working with "Big Data" problems that are typically high dimensional with multiple (but possibly incomplete) labelings and views. While other work has addressed each of these problems separately, in this paper we show how to address them together, namely semi-supervised dimension reduction for multi-task and multi-view learning (SSDR-MML), which performs optimization for dimension reduction and label inference in semi-supervised setting. The proposed framework is designed to handle both multi-task and multi-view learning settings, and can be easily adapted to many useful applications. Information obtained from all tasks and views is combined via reconstruction errors in a linear fashion that can be efficiently solved using an alternating optimization scheme. Our formulation has a number of advantages. We explicitly model the information combining mechanism as a data structure (a weight/nearest-neighbor matrix) which allows investigating fundamental questions in multi-task and multi-view learning. We address one such question by presenting a general measure to quantify the success of simultaneous learning of multiple tasks or from multiple views. We show that our SSDR-MML approach can outperform many state-of-the-art baseline methods and demonstrate the effectiveness of connecting dimension reduction and learning.