 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Random Matrix Approach to Neural Networks
Paper and Code

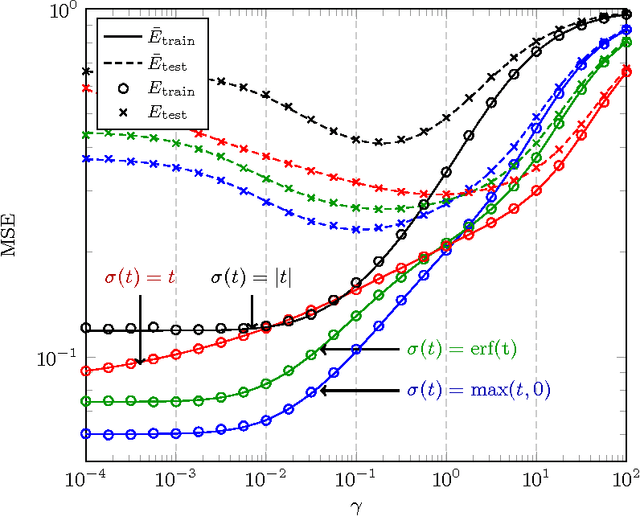
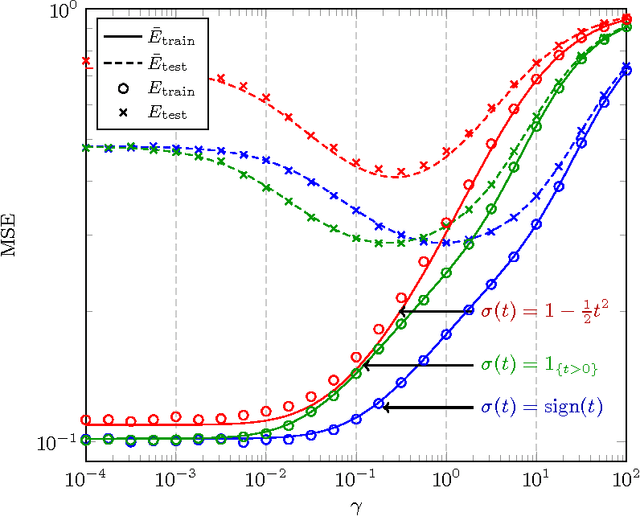
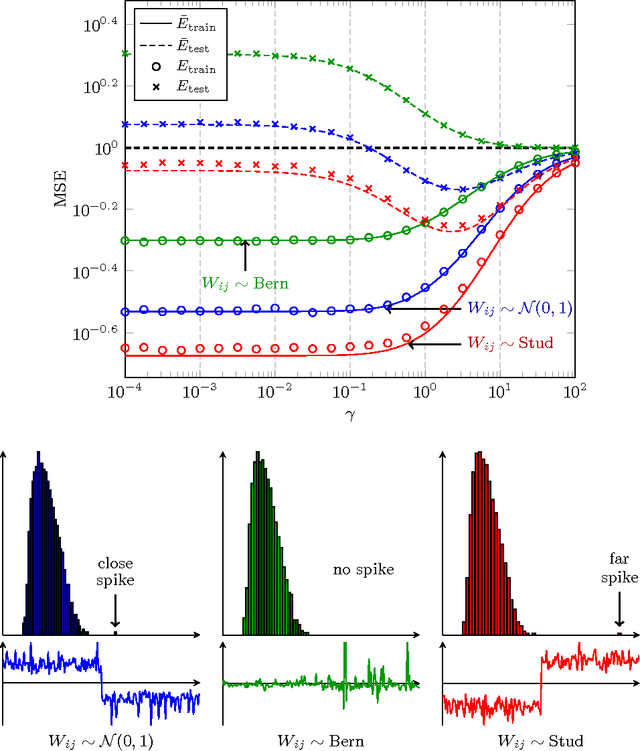
This article studies the Gram random matrix model $G=\frac1T\Sigma^{\rm T}\Sigma$, $\Sigma=\sigma(WX)$, classically found in the analysis of random feature maps and random neural networks, where $X=[x_1,\ldots,x_T]\in{\mathbb R}^{p\times T}$ is a (data) matrix of bounded norm, $W\in{\mathbb R}^{n\times p}$ is a matrix of independent zero-mean unit variance entries, and $\sigma:{\mathbb R}\to{\mathbb R}$ is a Lipschitz continuous (activation) function --- $\sigma(WX)$ being understood entry-wise. By means of a key concentration of measure lemma arising from non-asymptotic random matrix arguments, we prove that, as $n,p,T$ grow large at the same rate, the resolvent $Q=(G+\gamma I_T)^{-1}$, for $\gamma>0$, has a similar behavior as that met in sample covariance matrix models, involving notably the moment $\Phi=\frac{T}n{\mathbb E}[G]$, which provides in passing a deterministic equivalent for the empirical spectral measure of $G$. Application-wise, this result enables the estimation of the asymptotic performance of single-layer random neural networks. This in turn provides practical insights into the underlying mechanisms into play in random neural networks, entailing several unexpected consequences, as well as a fast practical means to tune the network hyperparameters.