Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA random energy approach to deep learning
Paper and Code
Dec 17, 2021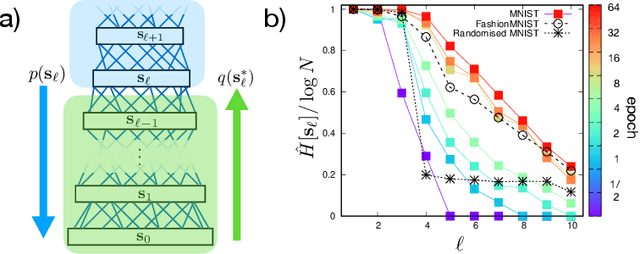
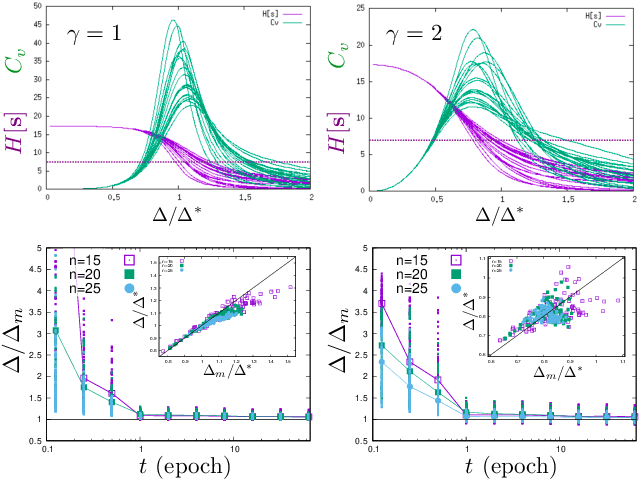
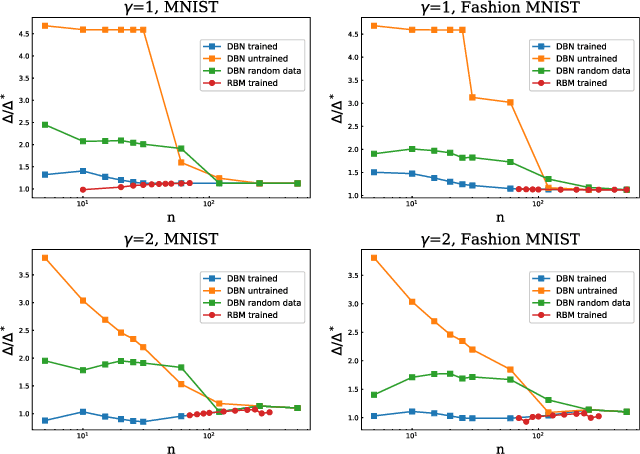
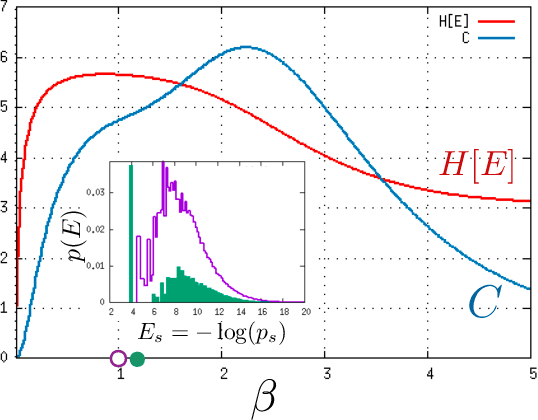
We study a generic ensemble of deep belief networks which is parametrized by the distribution of energy levels of the hidden states of each layer. We show that, within a random energy approach, statistical dependence can propagate from the visible to deep layers only if each layer is tuned close to the critical point during learning. As a consequence, efficiently trained learning machines are characterised by a broad distribution of energy levels. The analysis of Deep Belief Networks and Restricted Boltzmann Machines on different datasets confirms these conclusions.
* 16 pages, 4 figures
View paper on