 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Provably Convergent Information Bottleneck Solution via ADMM
Paper and Code
Feb 09, 2021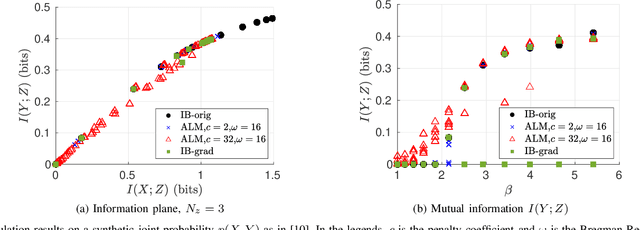
The Information bottleneck (IB) method enables optimizing over the trade-off between compression of data and prediction accuracy of learned representations, and has successfully and robustly been applied to both supervised and unsupervised representation learning problems. However, IB has several limitations. First, the IB problem is hard to optimize. The IB Lagrangian $\mathcal{L}_{IB}:=I(X;Z)-\beta I(Y;Z)$ is non-convex and existing solutions guarantee only local convergence. As a result, the obtained solutions depend on initialization. Second, the evaluation of a solution is also a challenging task. Conventionally, it resorts to characterizing the information plane, that is, plotting $I(Y;Z)$ versus $I(X;Z)$ for all solutions obtained from different initial points. Furthermore, the IB Lagrangian has phase transitions while varying the multiplier $\beta$. At phase transitions, both $I(X;Z)$ and $I(Y;Z)$ increase abruptly and the rate of convergence becomes significantly slow for existing solutions. Recent works with IB adopt variational surrogate bounds to the IB Lagrangian. Although allowing efficient optimization, how close are these surrogates to the IB Lagrangian is not clear. In this work, we solve the IB Lagrangian using augmented Lagrangian methods. With augmented variables, we show that the IB objective can be solved with the alternating direction method of multipliers (ADMM). Different from prior works, we prove that the proposed algorithm is consistently convergent, regardless of the value of $\beta$. Empirically, our gradient-descent-based method results in information plane points that are denser and comparable to those obtained through the conventional Blahut-Arimoto-based solvers.