Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Primer in BERTology: What we know about how BERT works
Paper and Code
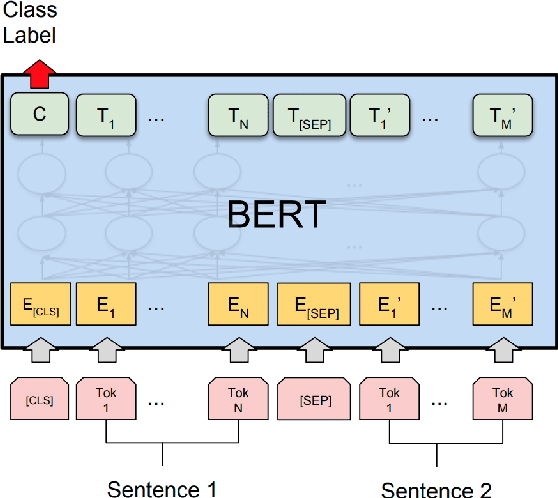
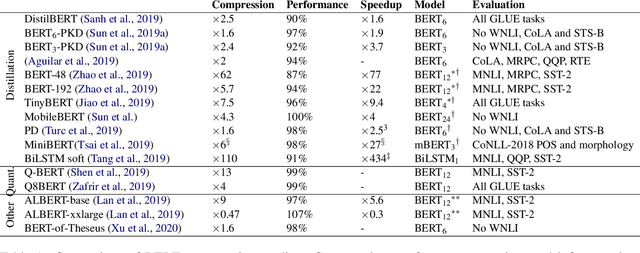
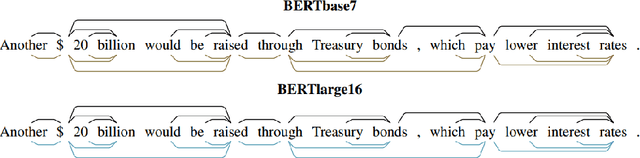
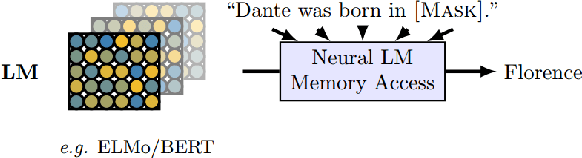
Transformer-based models are now widely used in NLP, but we still do not understand a lot about their inner workings. This paper describes what is known to date about the famous BERT model (Devlin et al. 2019), synthesizing over 40 analysis studies. We also provide an overview of the proposed modifications to the model and its training regime. We then outline the directions for further research.
View paper on