 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Online Method for Distributionally Deep Robust Optimization
Paper and Code
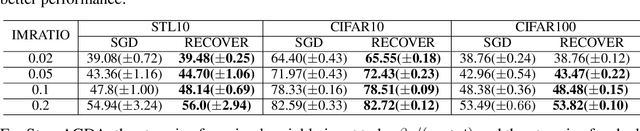

In this paper, we propose a practical online method for solving a distributionally robust optimization (DRO) for deep learning, which has important applications in machine learning for improving the robustness of neural networks. In the literature, most methods for solving DRO are based on stochastic primal-dual methods. However, primal-dual methods for deep DRO suffer from several drawbacks: (1) manipulating a high-dimensional dual variable corresponding to the size of data is time expensive; (2) they are not friendly to online learning where data is coming sequentially. To address these issues, we transform the min-max formulation into a minimization formulation and propose a practical duality-free online stochastic method for solving deep DRO with KL divergence regularization. The proposed online stochastic method resembles the practical stochastic Nesterov's method in several perspectives that are widely used for learning deep neural networks. Under a Polyak-Lojasiewicz (PL) condition, we prove that the proposed method can enjoy an optimal sample complexity and a better round complexity (the number of gradient evaluations divided by a fixed mini-batch size) with a moderate mini-batch size than existing algorithms for solving the min-max or min formulation of DRO. Of independent interest, the proposed method can be also used for solving a family of stochastic compositional problems.