 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA policy gradient approach for Finite Horizon Constrained Markov Decision Processes
Paper and Code
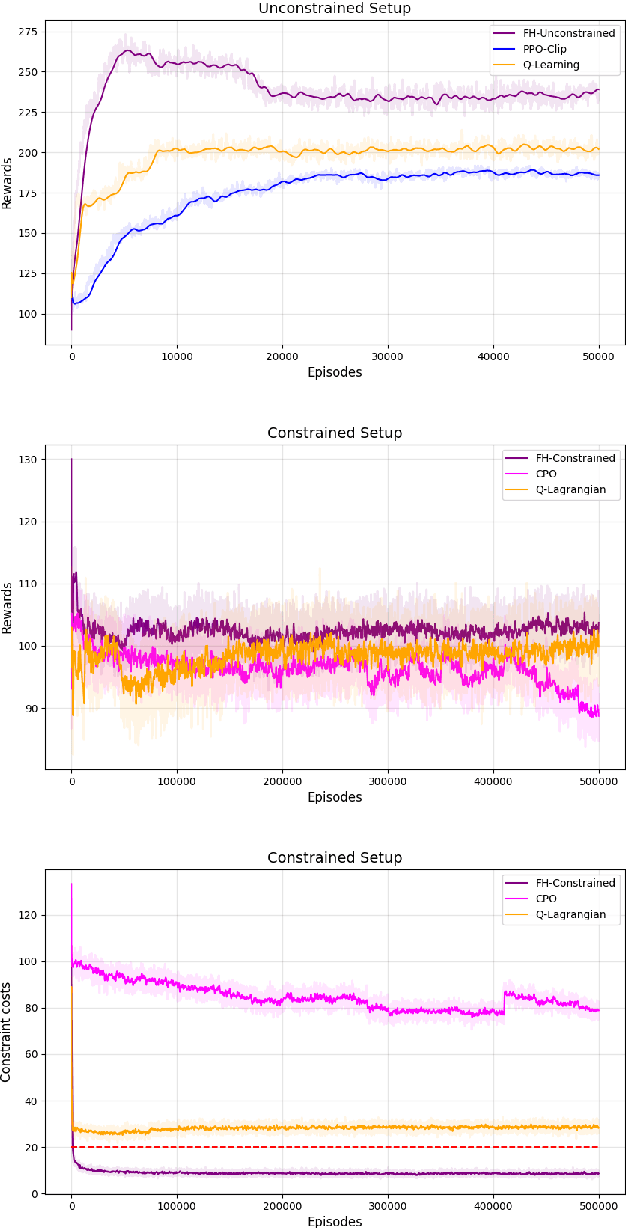
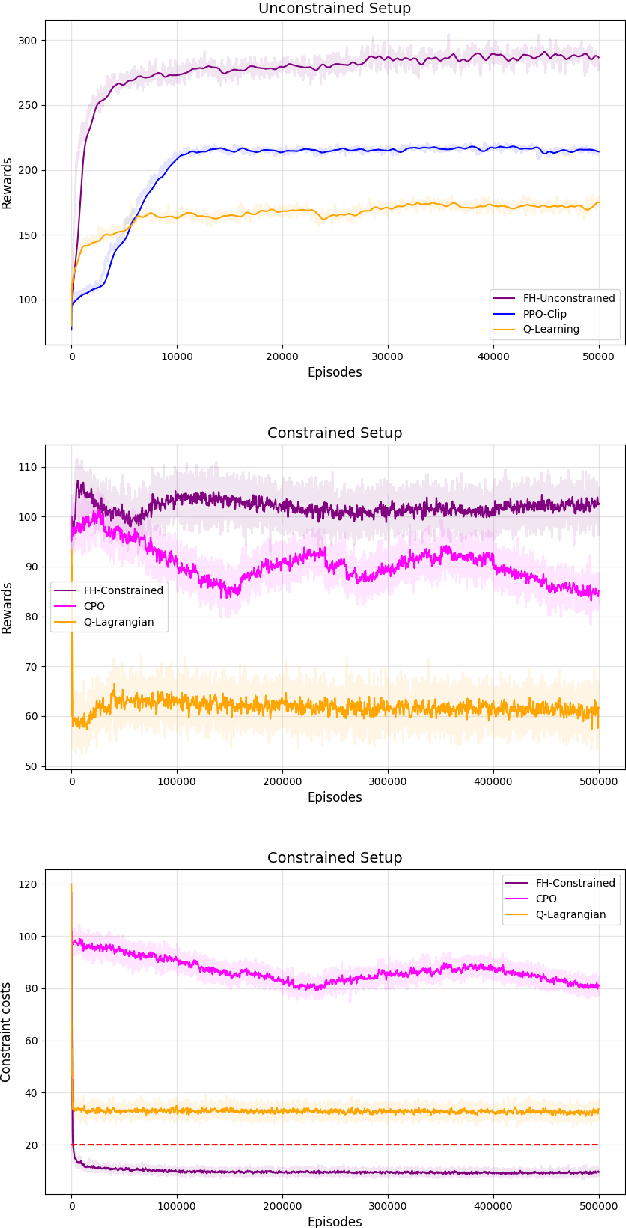
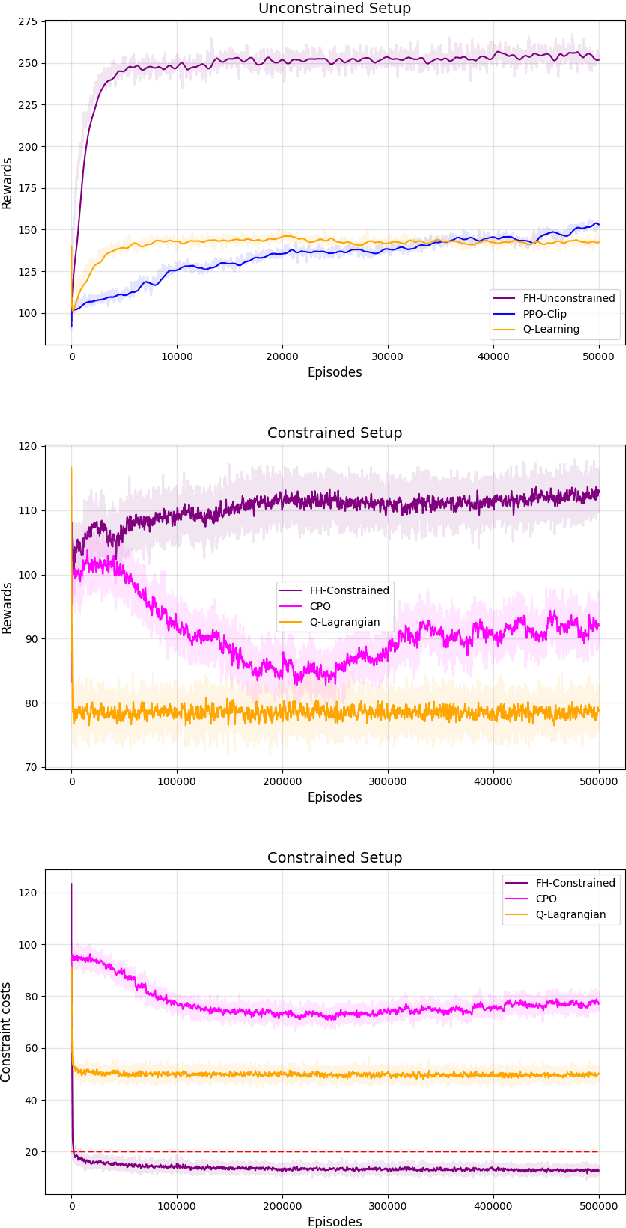
The infinite horizon setting is widely adopted for problems of reinforcement learning (RL). These invariably result in stationary policies that are optimal. In many situations, finite horizon control problems are of interest and for such problems, the optimal policies are time-varying in general. Another setting that has become popular in recent times is of Constrained Reinforcement Learning, where the agent maximizes its rewards while also aims to satisfy certain constraint criteria. However, this setting has only been studied in the context of infinite horizon MDPs where stationary policies are optimal. We present, for the first time, an algorithm for constrained RL in the Finite Horizon Setting where the horizon terminates after a fixed (finite) time. We use function approximation in our algorithm which is essential when the state and action spaces are large or continuous and use the policy gradient method to find the optimal policy. The optimal policy that we obtain depends on the stage and so is time-dependent. To the best of our knowledge, our paper presents the first policy gradient algorithm for the finite horizon setting with constraints. We show the convergence of our algorithm to an optimal policy. We further present a sample complexity result for our algorithm in the unconstrained (i.e., the regular finite horizon MDP) setting. We also compare and analyze the performance of our algorithm through experiments and show that our algorithm performs better than other well known algorithms.