 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Co-design Peta-scale Heterogeneous Cluster for Deep Learning Training
Paper and Code
May 18, 2018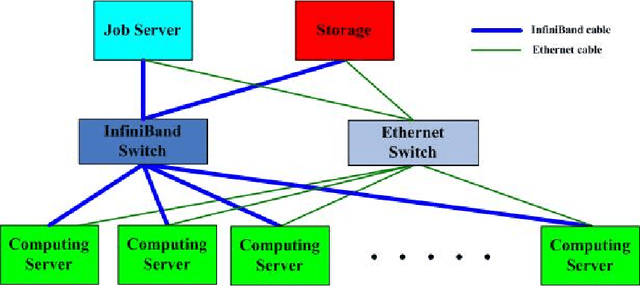
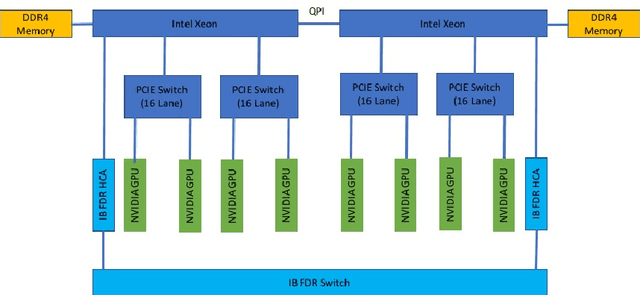
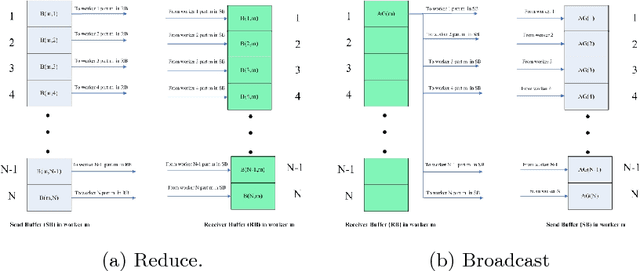
Large scale deep Convolution Neural Networks (CNNs) increasingly demands the computing power. It is key for researchers to own a great powerful computing platform to leverage deep learning (DL) advancing.On the other hand, as the commonly-used accelerator, the commodity GPUs cards of new generations are more and more expensive. Consequently, it is of importance to design an affordable distributed heterogeneous system that provides powerful computational capacity and develop a well-suited software that efficiently utilizes its computational capacity. In this paper, we present our co-design distributed system including a peta-scale GPU cluster, called "Manoa". Based on properties and topology of Manoa, we first propose job server framework and implement it, named "MiMatrix". The central node of MiMatrix, referred to as the job server, undertakes all of controlling, scheduling and monitoring, and I/O tasks without weight data transfer for AllReduce processing in each iteration. Therefore, MiMatrix intrinsically solves the bandwidth bottleneck of central node in parameter server framework that is widely used in distributed DL tasks. Meanwhile, we also propose a new AllReduce algorithm, GPUDirect RDMA-Aware AllReduce~(GDRAA), in which both computation and handshake message are O(1) and the number of synchronization is two in each iteration that is a theoretical minimum number. Owe to the dedicated co-design distributed system, MiMatrix efficiently makes use of the Manoa's computational capacity and bandwidth. We benchmark Manoa Resnet50 and Resenet101 on Imagenet-1K dataset. Some of results have demonstrated state-of-the-art.