 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Topic-Attention Model for Medical Term Abbreviation Disambiguation
Paper and Code


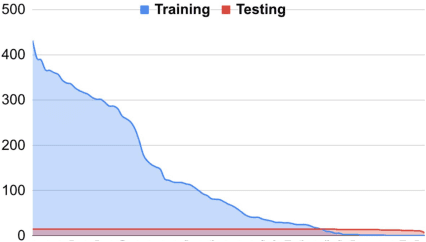
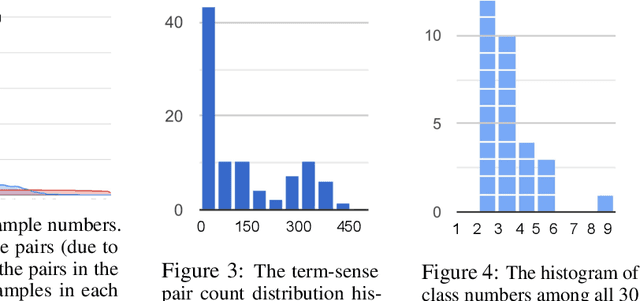
Automated analysis of clinical notes is attracting increasing attention. However, there has not been much work on medical term abbreviation disambiguation. Such abbreviations are abundant, and highly ambiguous, in clinical documents. One of the main obstacles is the lack of large scale, balance labeled data sets. To address the issue, we propose a few-shot learning approach to take advantage of limited labeled data. Specifically, a neural topic-attention model is applied to learn improved contextualized sentence representations for medical term abbreviation disambiguation. Another vital issue is that the existing scarce annotations are noisy and missing. We re-examine and correct an existing dataset for training and collect a test set to evaluate the models fairly especially for rare senses. We train our model on the training set which contains 30 abbreviation terms as categories (on average, 479 samples and 3.24 classes in each term) selected from a public abbreviation disambiguation dataset, and then test on a manually-created balanced dataset (each class in each term has 15 samples). We show that enhancing the sentence representation with topic information improves the performance on small-scale unbalanced training datasets by a large margin, compared to a number of baseline models.