 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA neural network with feature sparsity
Paper and Code
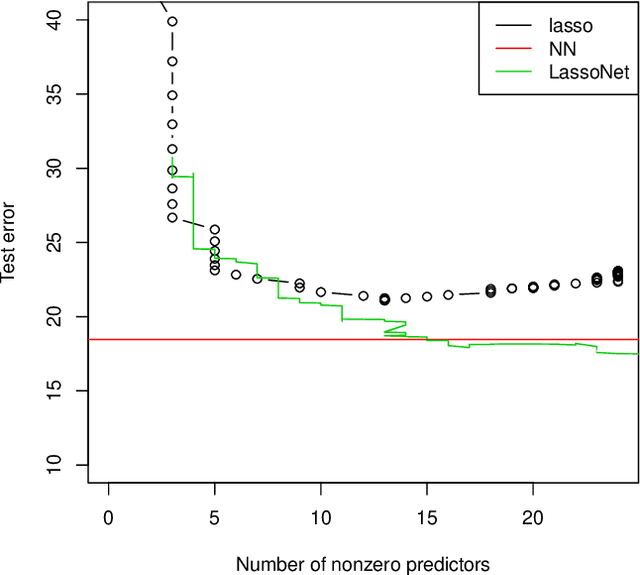
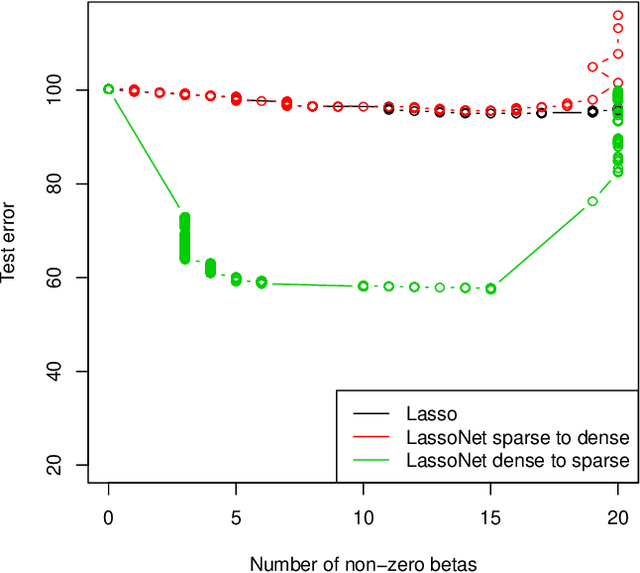
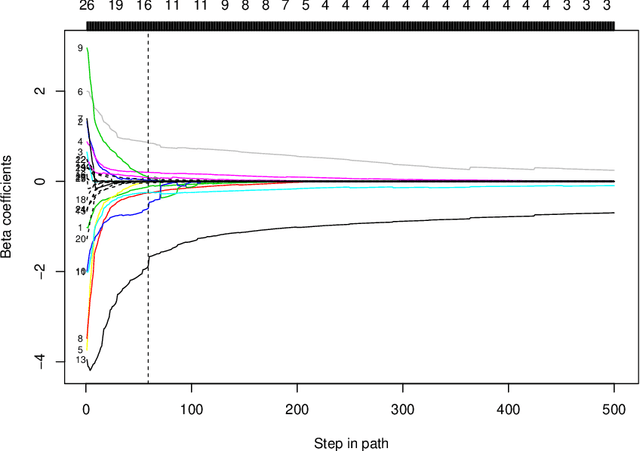
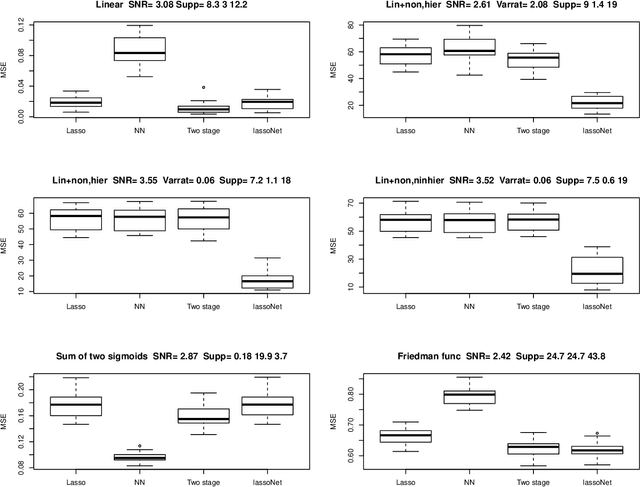
We propose a neural network model, with a separate linear (residual) term, that explicitly bounds the input layer weights for a feature by the linear weight for that feature. The model can be seen as a modification of so-called residual neural networks to produce a path of models that are feature-sparse, that is, use only a subset of the features. This is analogous to the solution path from the usual Lasso ($\ell_1$-regularized) linear regression. We call the proposed procedure "LassoNet" and develop a projected proximal gradient algorithm for its optimization. This approach can sometimes give as low or lower test error than a standard neural network, and its feature selection provides more interpretable solutions. We illustrate the method using both simulated and real data examples, and show that it is often able to achieve competitive performance with a much smaller number of input features.