 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Model for Joint Document and Snippet Ranking in Question Answering for Large Document Collections
Paper and Code
Jun 16, 2021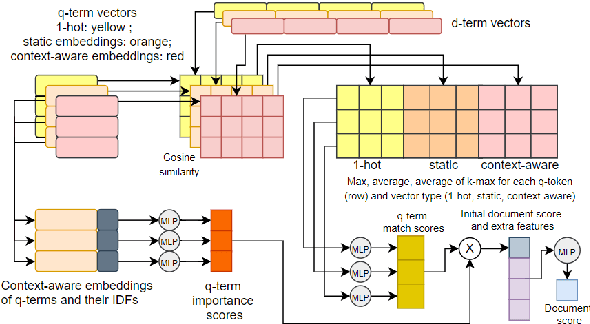

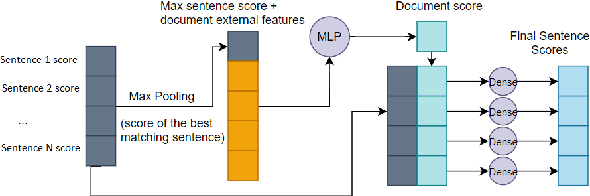

Question answering (QA) systems for large document collections typically use pipelines that (i) retrieve possibly relevant documents, (ii) re-rank them, (iii) rank paragraphs or other snippets of the top-ranked documents, and (iv) select spans of the top-ranked snippets as exact answers. Pipelines are conceptually simple, but errors propagate from one component to the next, without later components being able to revise earlier decisions. We present an architecture for joint document and snippet ranking, the two middle stages, which leverages the intuition that relevant documents have good snippets and good snippets come from relevant documents. The architecture is general and can be used with any neural text relevance ranker. We experiment with two main instantiations of the architecture, based on POSIT-DRMM (PDRMM) and a BERT-based ranker. Experiments on biomedical data from BIOASQ show that our joint models vastly outperform the pipelines in snippet retrieval, the main goal for QA, with fewer trainable parameters, also remaining competitive in document retrieval. Furthermore, our joint PDRMM-based model is competitive with BERT-based models, despite using orders of magnitude fewer parameters. These claims are also supported by human evaluation on two test batches of BIOASQ. To test our key findings on another dataset, we modified the Natural Questions dataset so that it can also be used for document and snippet retrieval. Our joint PDRMM-based model again outperforms the corresponding pipeline in snippet retrieval on the modified Natural Questions dataset, even though it performs worse than the pipeline in document retrieval. We make our code and the modified Natural Questions dataset publicly available.