 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Minimum Discounted Reward Hamilton-Jacobi Formulation for Computing Reachable Sets
Paper and Code
Sep 03, 2018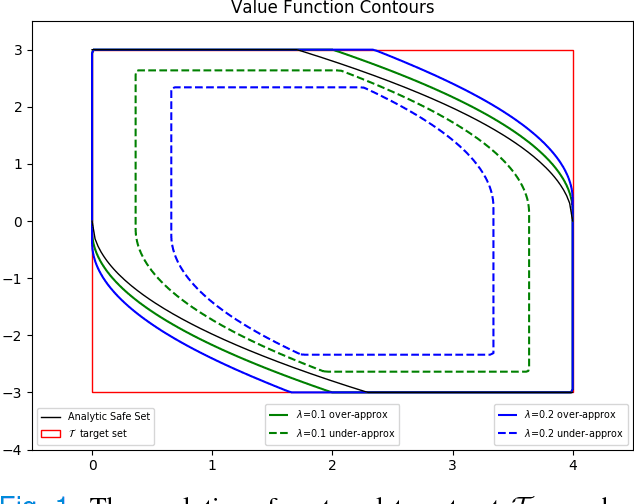
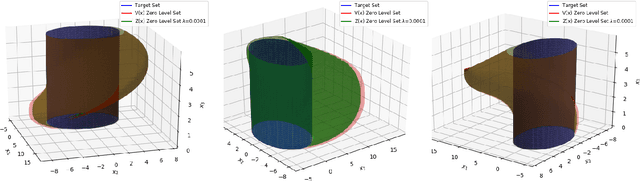
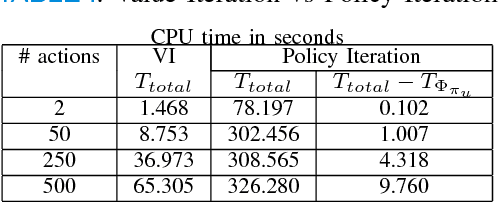
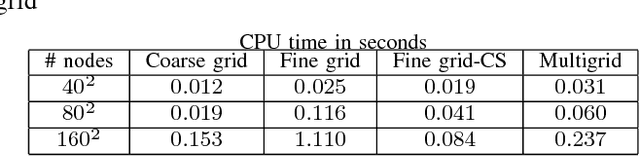
We propose a novel formulation for approximating reachable sets through a minimum discounted reward optimal control problem. The formulation yields a continuous solution that can be obtained by solving a Hamilton-Jacobi equation. Furthermore, the numerical approximation to this solution can be obtained as the unique fixed-point to a contraction mapping. This allows for more efficient solution methods that could not be applied under traditional formulations for solving reachable sets. In addition, this formulation provides a link between reinforcement learning and learning reachable sets for systems with unknown dynamics, allowing algorithms from the former to be applied to the latter. We use two benchmark examples, double integrator, and pursuit-evasion games, to show the correctness of the formulation as well as its strengths in comparison to previous work.