 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mini-Block Natural Gradient Method for Deep Neural Networks
Paper and Code
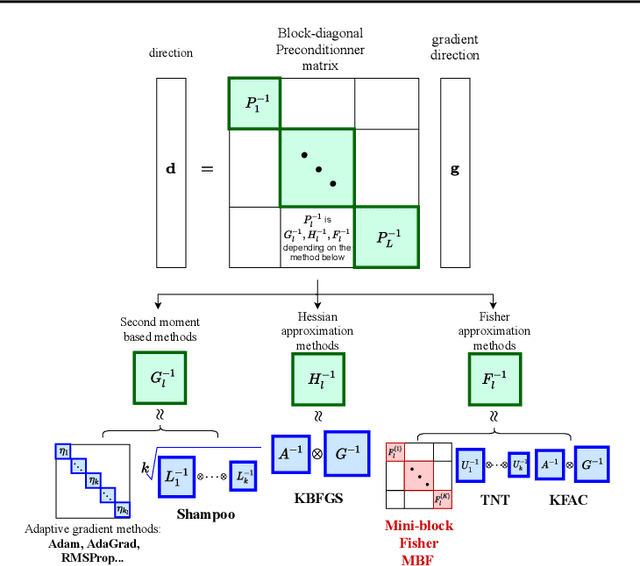
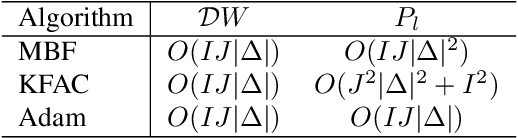
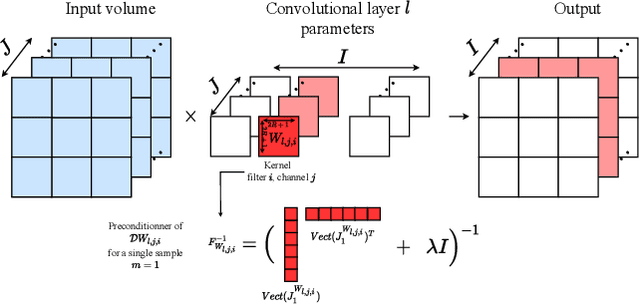

The training of deep neural networks (DNNs) is currently predominantly done using first-order methods. Some of these methods (e.g., Adam, AdaGrad, and RMSprop, and their variants) incorporate a small amount of curvature information by using a diagonal matrix to precondition the stochastic gradient. Recently, effective second-order methods, such as KFAC, K-BFGS, Shampoo, and TNT, have been developed for training DNNs, by preconditioning the stochastic gradient by layer-wise block-diagonal matrices. Here we propose and analyze the convergence of an approximate natural gradient method, mini-block Fisher (MBF), that lies in between these two classes of methods. Specifically, our method uses a block-diagonal approximation to the Fisher matrix, where for each layer in the DNN, whether it is convolutional or feed-forward and fully connected, the associated diagonal block is also block-diagonal and is composed of a large number of mini-blocks of modest size. Our novel approach utilizes the parallelism of GPUs to efficiently perform computations on the large number of matrices in each layer. Consequently, MBF's per-iteration computational cost is only slightly higher than it is for first-order methods. Finally, the performance of our proposed method is compared to that of several baseline methods, on both Auto-encoder and CNN problems, to validate its effectiveness both in terms of time efficiency and generalization power.