 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Microprocessor implemented in 65nm CMOS with Configurable and Bit-scalable Accelerator for Programmable In-memory Computing
Paper and Code
Nov 09, 2018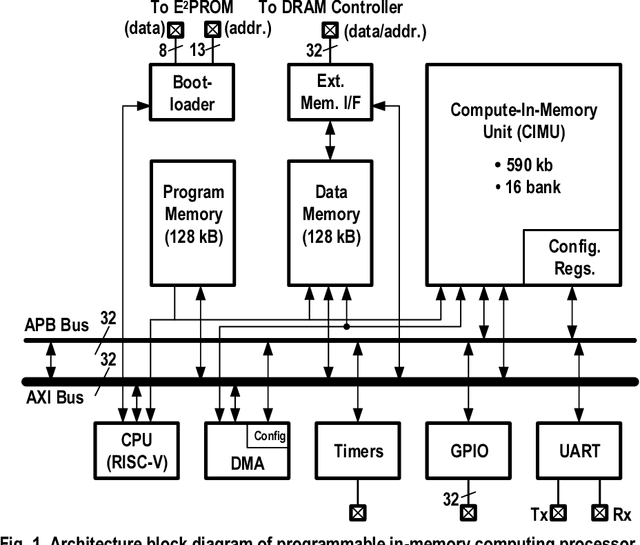
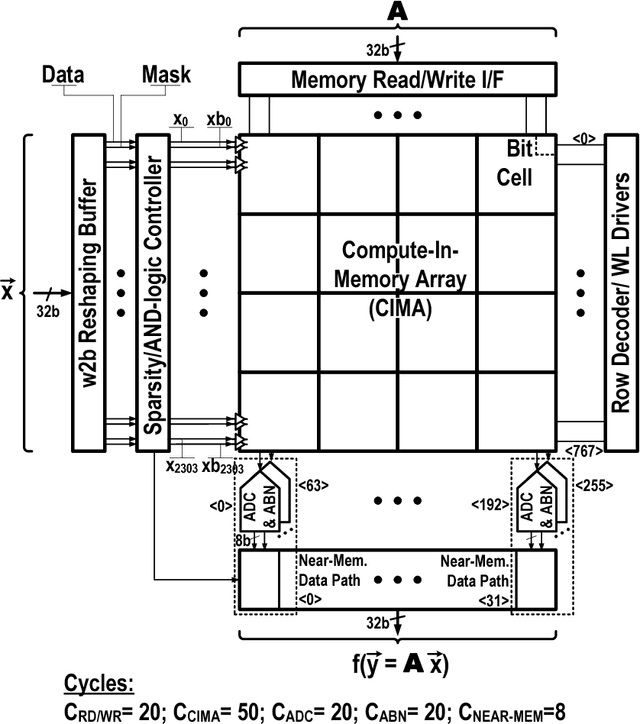
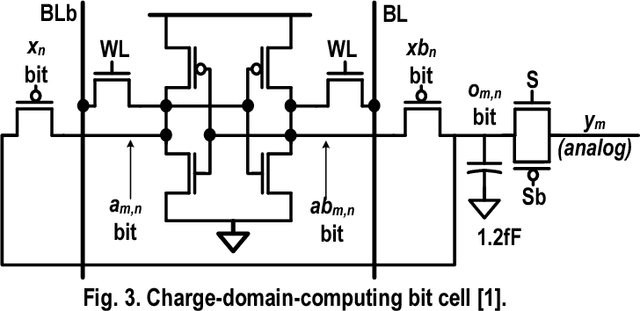
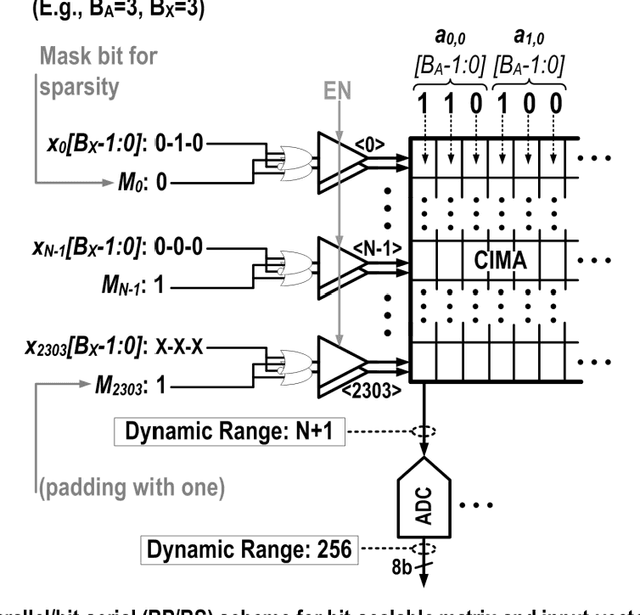
This paper presents a programmable in-memory-computing processor, demonstrated in a 65nm CMOS technology. For data-centric workloads, such as deep neural networks, data movement often dominates when implemented with today's computing architectures. This has motivated spatial architectures, where the arrangement of data-storage and compute hardware is distributed and explicitly aligned to the computation dataflow, most notably for matrix-vector multiplication. In-memory computing is a spatial architecture where processing elements correspond to dense bit cells, providing local storage and compute, typically employing analog operation. Though this raises the potential for high energy efficiency and throughput, analog operation has significantly limited robustness, scale, and programmability. This paper describes a 590kb in-memory-computing accelerator integrated in a programmable processor architecture, by exploiting recent approaches to charge-domain in-memory computing. The architecture takes the approach of tight coupling with an embedded CPU, through accelerator interfaces enabling integration in the standard processor memory space. Additionally, a near-memory-computing datapath both enables diverse computations locally, to address operations required across applications, and enables bit-precision scalability for matrix/input-vector elements, through a bit-parallel/bit-serial (BP/BS) scheme. Chip measurements show an energy efficiency of 152/297 1b-TOPS/W and throughput of 4.7/1.9 1b-TOPS (scaling linearly with the matrix/input-vector element precisions) at VDD of 1.2/0.85V. Neural network demonstrations with 1-b/4-b weights and activations for CIFAR-10 classification consume 5.3/105.2 $\mu$J/image at 176/23 fps, with accuracy at the level of digital/software implementation (89.3/92.4 $\%$ accuracy).