 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Little Is Enough: Circumventing Defenses For Distributed Learning
Paper and Code
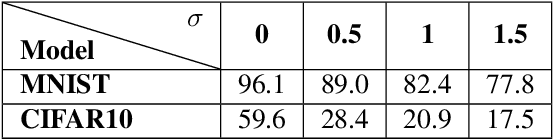
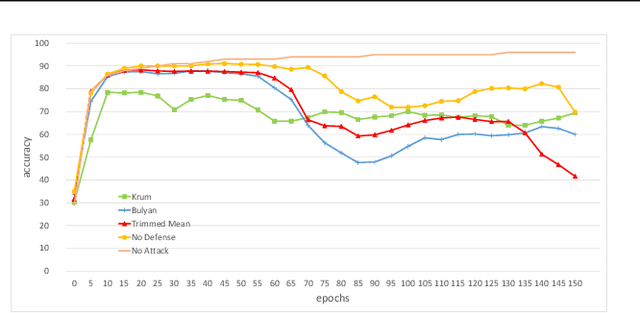
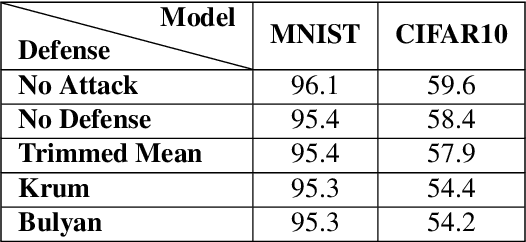
Distributed learning is central for large-scale training of deep-learning models. However, they are exposed to a security threat in which Byzantine participants can interrupt or control the learning process. Previous attack models and their corresponding defenses assume that the rogue participants are (a) omniscient (know the data of all other participants), and (b) introduce large change to the parameters. We show that small but well-crafted changes are sufficient, leading to a novel non-omniscient attack on distributed learning that go undetected by all existing defenses. We demonstrate our attack method works not only for preventing convergence but also for repurposing of the model behavior (backdooring). We show that 20% of corrupt workers are sufficient to degrade a CIFAR10 model accuracy by 50%, as well as to introduce backdoors into MNIST and CIFAR10 models without hurting their accuracy