 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-scale Dataset and Benchmark for Similar Trademark Retrieval
Paper and Code
Oct 14, 2017
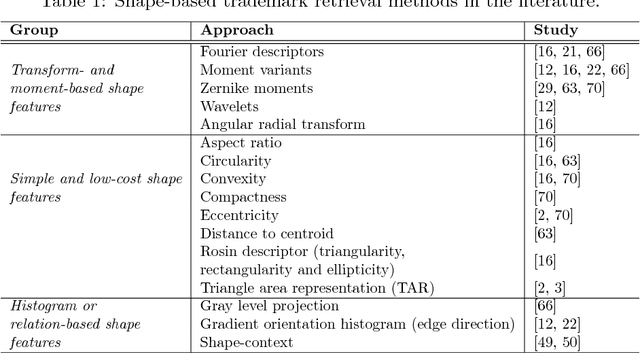


Trademark retrieval (TR) has become an important yet challenging problem due to an ever increasing trend in trademark applications and infringement incidents. There have been many promising attempts for the TR problem, which, however, fell impracticable since they were evaluated with limited and mostly trivial datasets. In this paper, we provide a large-scale dataset with benchmark queries with which different TR approaches can be evaluated systematically. Moreover, we provide a baseline on this benchmark using the widely-used methods applied to TR in the literature. Furthermore, we identify and correct two important issues in TR approaches that were not addressed before: reversal of contrast, and presence of irrelevant text in trademarks severely affect the TR methods. Lastly, we applied deep learning, namely, several popular Convolutional Neural Network models, to the TR problem. To the best of the authors, this is the first attempt to do so.