Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Knowledge-Grounded Multimodal Search-Based Conversational Agent
Paper and Code
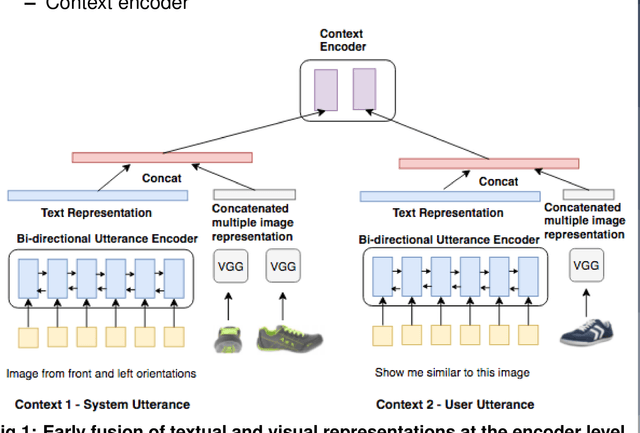
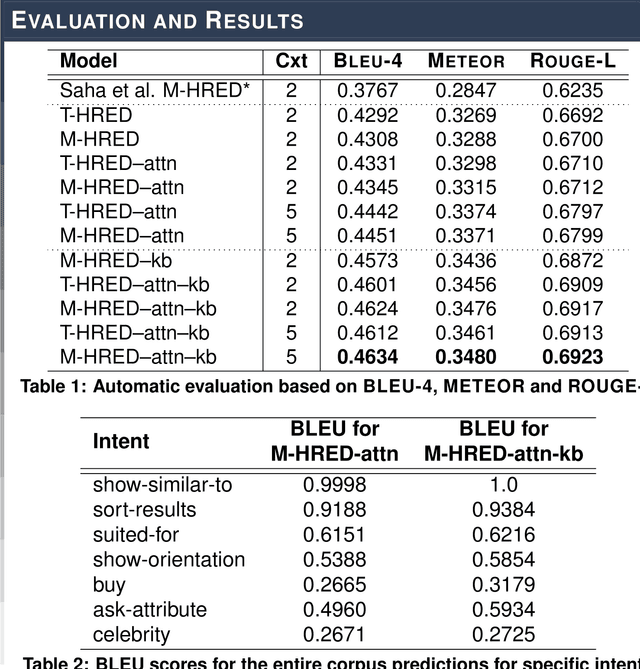
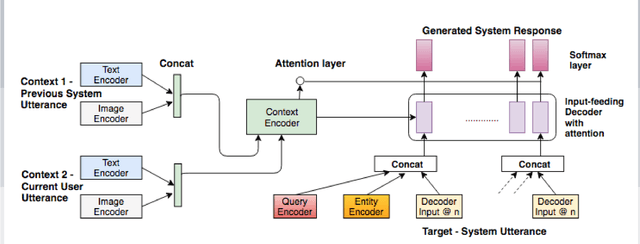
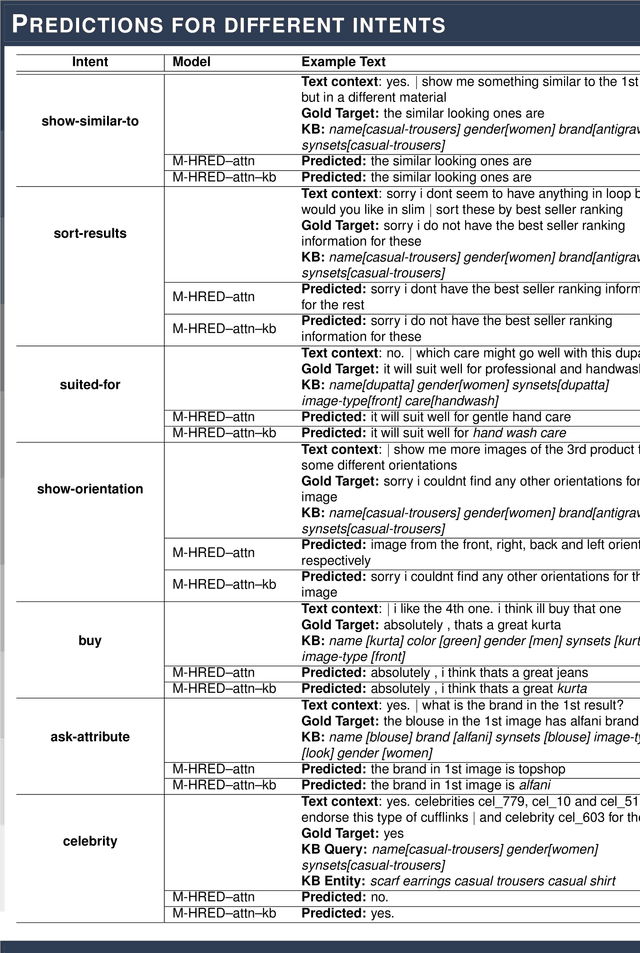
Multimodal search-based dialogue is a challenging new task: It extends visually grounded question answering systems into multi-turn conversations with access to an external database. We address this new challenge by learning a neural response generation system from the recently released Multimodal Dialogue (MMD) dataset (Saha et al., 2017). We introduce a knowledge-grounded multimodal conversational model where an encoded knowledge base (KB) representation is appended to the decoder input. Our model substantially outperforms strong baselines in terms of text-based similarity measures (over 9 BLEU points, 3 of which are solely due to the use of additional information from the KB.
View paper on