 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Human Ear Reconstruction Autoencoder
Paper and Code
Oct 07, 2020


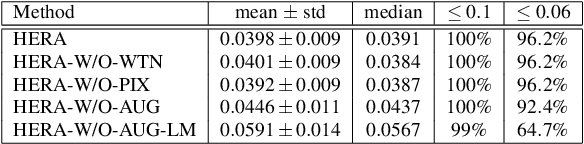
The ear, as an important part of the human head, has received much less attention compared to the human face in the area of computer vision. Inspired by previous work on monocular 3D face reconstruction using an autoencoder structure to achieve self-supervised learning, we aim to utilise such a framework to tackle the 3D ear reconstruction task, where more subtle and difficult curves and features are present on the 2D ear input images. Our Human Ear Reconstruction Autoencoder (HERA) system predicts 3D ear poses and shape parameters for 3D ear meshes, without any supervision to these parameters. To make our approach cover the variance for in-the-wild images, even grayscale images, we propose an in-the-wild ear colour model. The constructed end-to-end self-supervised model is then evaluated both with 2D landmark localisation performance and the appearance of the reconstructed 3D ears.