 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA generalization gap estimation for overparameterized models via the Langevin functional variance
Paper and Code
Dec 26, 2021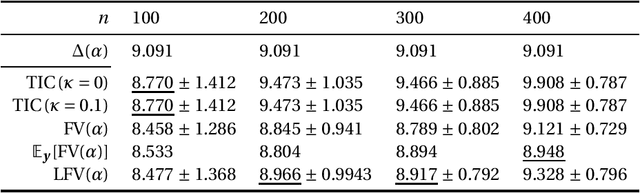

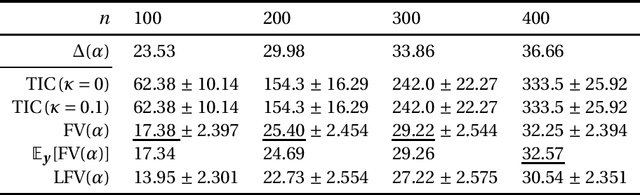

This paper discusses the estimation of the generalization gap, the difference between a generalization error and an empirical error, for overparameterized models (e.g., neural networks). We first show that a functional variance, a key concept in defining a widely-applicable information criterion, characterizes the generalization gap even in overparameterized settings where a conventional theory cannot be applied. We also propose a computationally efficient approximation of the function variance, the Langevin approximation of the functional variance (Langevin FV). This method leverages only the $1$st-order gradient of the squared loss function, without referencing the $2$nd-order gradient; this ensures that the computation is efficient and the implementation is consistent with gradient-based optimization algorithms. We demonstrate the Langevin FV numerically by estimating the generalization gaps of overparameterized linear regression and non-linear neural network models.