 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework of Randomized Selection Based Certified Defenses Against Data Poisoning Attacks
Paper and Code
Oct 13, 2020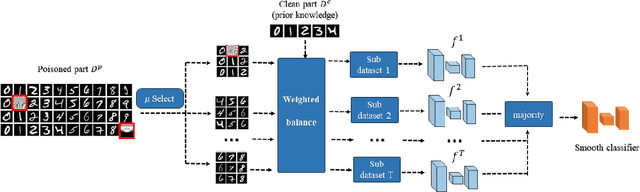
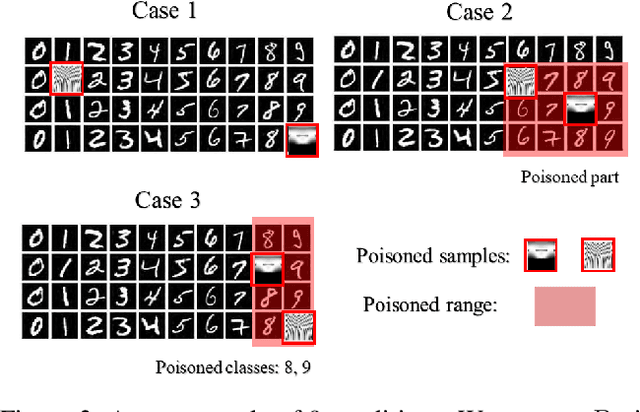
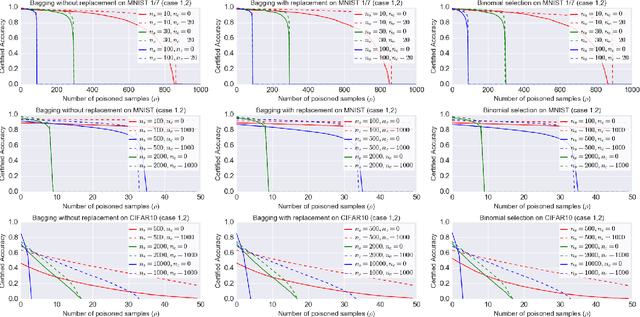
Neural network classifiers are vulnerable to data poisoning attacks, as attackers can degrade or even manipulate their predictions thorough poisoning only a few training samples. However, the robustness of heuristic defenses is hard to measure. Random selection based defenses can achieve certified robustness by averaging the classifiers' predictions on the sub-datasets sampled from the training set. This paper proposes a framework of random selection based certified defenses against data poisoning attacks. Specifically, we prove that the random selection schemes that satisfy certain conditions are robust against data poisoning attacks. We also derive the analytical form of the certified radius for the qualified random selection schemes. The certified radius of bagging derived by our framework is tighter than the previous work. Our framework allows users to improve robustness by leveraging prior knowledge about the training set and the poisoning model. Given higher level of prior knowledge, we can achieve higher certified accuracy both theoretically and practically. According to the experiments on three benchmark datasets: MNIST 1/7, MNIST, and CIFAR-10, our method outperforms the state-of-the-art.