 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA First Step Towards Distribution Invariant Regression Metrics
Paper and Code
Sep 10, 2020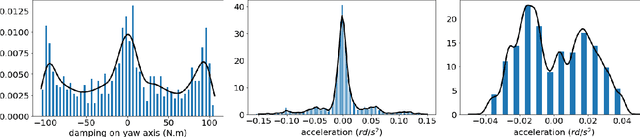
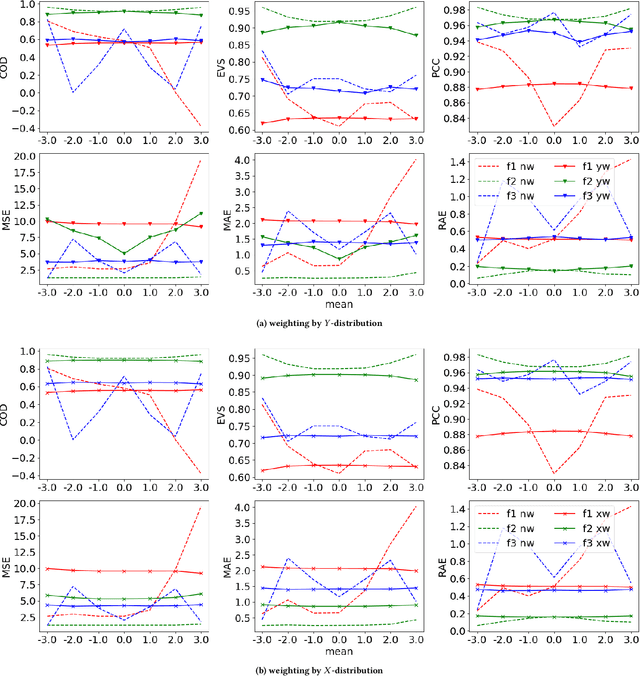
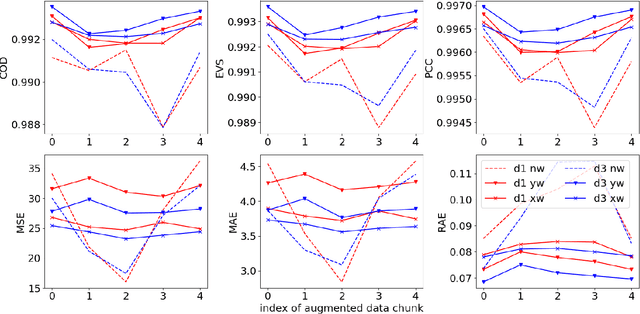
Regression evaluation has been performed for decades. Some metrics have been identified to be robust against shifting and scaling of the data but considering the different distributions of data is much more difficult to address (imbalance problem) even though it largely impacts the comparability between evaluations on different datasets. In classification, it has been stated repeatedly that performance metrics like the F-Measure and Accuracy are highly dependent on the class distribution and that comparisons between different datasets with different distributions are impossible. We show that the same problem exists in regression. The distribution of odometry parameters in robotic applications can for example largely vary between different recording sessions. Here, we need regression algorithms that either perform equally well for all function values, or that focus on certain boundary regions like high speed. This has to be reflected in the evaluation metric. We propose the modification of established regression metrics by weighting with the inverse distribution of function values $Y$ or the samples $X$ using an automatically tuned Gaussian kernel density estimator. We show on synthetic and robotic data in reproducible experiments that classical metrics behave wrongly, whereas our new metrics are less sensitive to changing distributions, especially when correcting by the marginal distribution in $X$. Our new evaluation concept enables the comparison of results between different datasets with different distributions. Furthermore, it can reveal overfitting of a regression algorithm to overrepresented target values. As an outcome, non-overfitting regression algorithms will be more likely chosen due to our corrected metrics.