 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fine-to-Coarse Convolutional Neural Network for 3D Human Action Recognition
Paper and Code
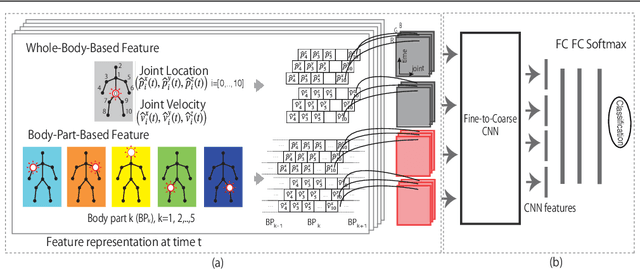
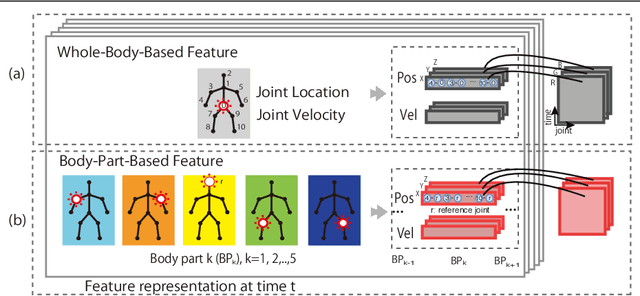
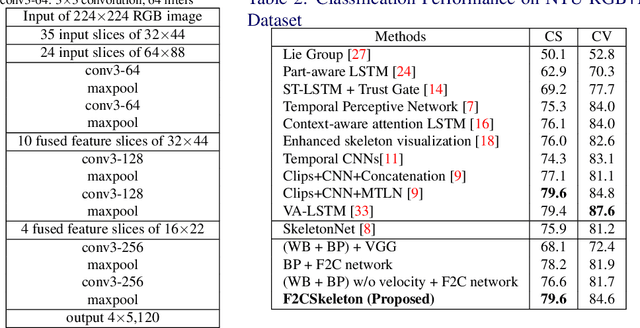
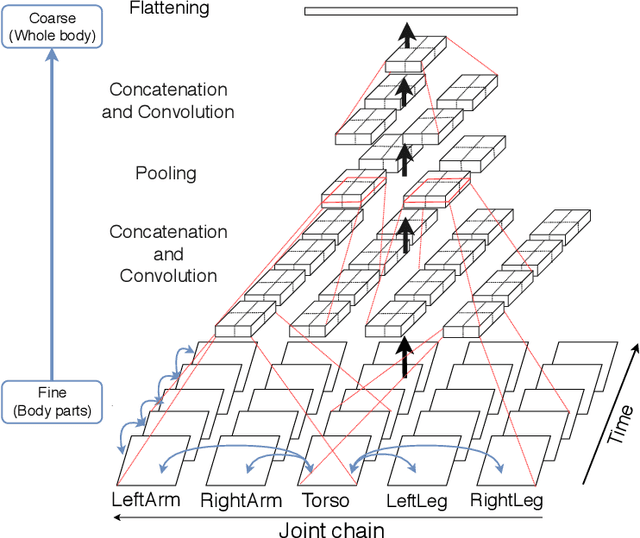
This paper presents a new framework for human action recognition from a 3D skeleton sequence. Previous studies do not fully utilize the temporal relationships between video segments in a human action. Some studies successfully used very deep Convolutional Neural Network (CNN) models but often suffer from the data insufficiency problem. In this study, we first segment a skeleton sequence into distinct temporal segments in order to exploit the correlations between them. The temporal and spatial features of a skeleton sequence are then extracted simultaneously by utilizing a fine-to-coarse (F2C) CNN architecture optimized for human skeleton sequences. We evaluate our proposed method on NTU RGB+D and SBU Kinect Interaction dataset. It achieves 79.6% and 84.6% of accuracies on NTU RGB+D with cross-object and cross-view protocol, respectively, which are almost identical with the state-of-the-art performance. In addition, our method significantly improves the accuracy of the actions in two-person interactions.